
Try yourself: Try the interactive liveness detection demo in the Facial Liveness Verification lab.
Face Verification System Internals
Facial verification is now embedded in some of the most sensitive authentication decisions an organization makes: financial account opening, identity proofing for regulated services, physical access control, and employee onboarding. To users, the experience is a selfie and a result. Under the surface, it is a multi-stage pipeline that must work reliably across different cameras, lighting conditions, face angles, and demographic variation, while simultaneously resisting spoofing attacks that are becoming easier to execute and harder to detect. Understanding how that pipeline works is not an academic exercise — it is what separates a system that can be defended from one whose failure modes are invisible.
This article walks through a facial verification system from image capture to identity decision. It covers how faces are detected, aligned, and converted into mathematical embeddings; how users are enrolled and how biometric templates are stored and protected; how similarity scores become access decisions; how liveness detection works and where it breaks down; and how deepfake and injection attacks have changed the threat landscape in 2024–2026. The goal is a complete, accurate technical model of what a facial verification system is doing at each step — and why each step is designed the way it is.
The Facial Recognition Pipeline
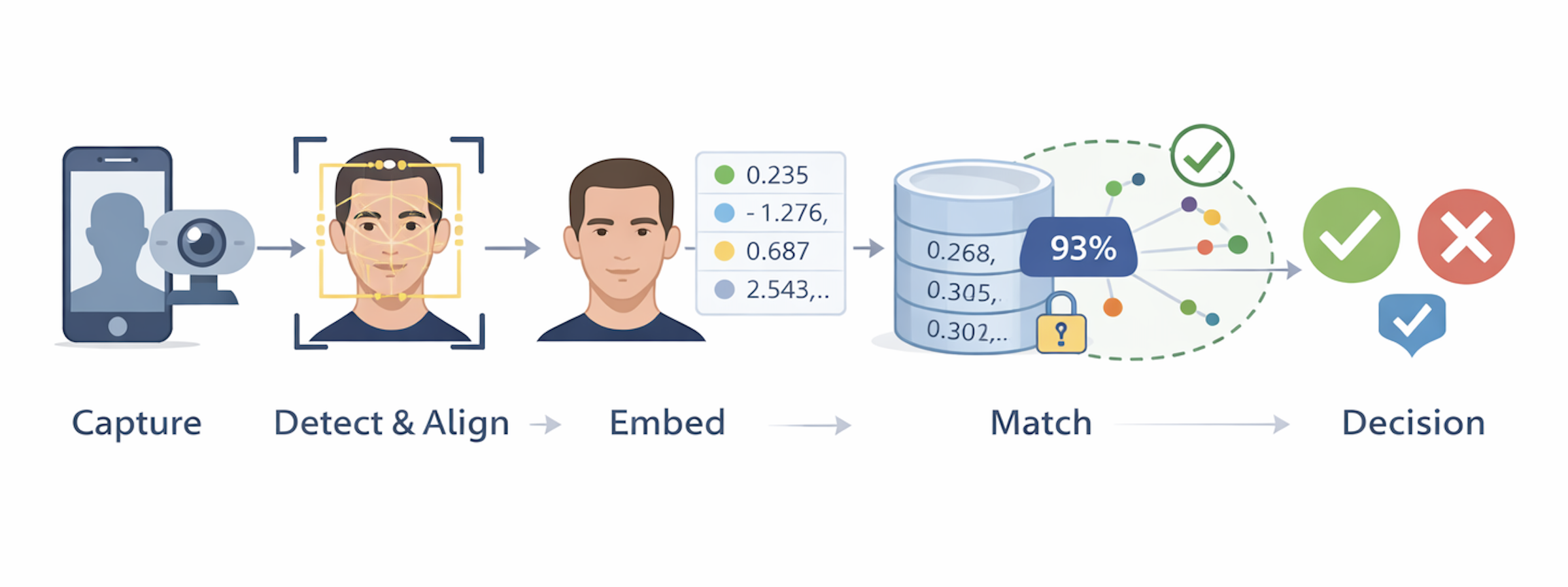
A facial recognition system is best understood as a pipeline that transforms raw visual input into an identity decision through a sequence of distinct stages. Different vendors implement this pipeline in different ways, but most modern systems share the same fundamental structure. Thinking in terms of pipeline stages makes the overall system much easier to reason about from a security or architecture perspective — it makes clear where each type of failure or attack enters the system and what defenses apply at each layer.
The pipeline moves through five broad stages:
1. Capture. A camera collects an image or short video of a person’s face. Real-world environments vary widely in lighting, motion, and sensor quality. This step shapes the quality of everything that follows.
2. Face Detection and Alignment. The system determines whether a face is present, where it is, and normalizes it — rotating, cropping, and scaling to produce a standardized “face chip” that downstream models can process consistently.
3. Embedding Generation. The normalized face is passed through a neural network that converts it into a compact numerical vector called an embedding. The system stops working with images and starts working with numbers. Identity is now encoded as a point in high-dimensional space.
4. Matching. The new embedding is compared against stored references. In verification (1:1), it is compared against a single enrolled embedding for a claimed identity. In identification (1:N), it is compared against many embeddings to find the closest match. Similarity is measured geometrically.
5. Decision and Policy. The system applies thresholds and contextual signals to decide whether to grant access, request a second factor, or deny. This step is a policy decision as much as a technical one.
These five stages divide into two conceptual halves. The first — perception and representation — includes capture, detection, alignment, and embedding generation. Its job is to convert messy real-world input into clean, comparable data. The second — identity reasoning — includes matching, thresholding, and decision-making. Its job is to interpret the embedding in the context of stored identities and security policy. Liveness detection and deepfake defenses are protective layers that surround both halves, since attacks can enter at either the capture stage or the matching stage.
Face Capture & Detection

Before any recognition can happen, the system must turn a real-world scene into a clean, standardized face image. This step receives less attention than machine learning, but it is one of the most important in the entire pipeline. Poor input quality propagates forward and produces bad embeddings even when the recognition model itself is excellent. Most real-world failures in deployed facial recognition trace back to this stage, not to the neural network.
Sensor types
The physical sensor determines what information is available to the pipeline. Three sensor modalities are common in production systems:
RGB cameras are standard visible-light cameras — smartphone front cameras, laptop webcams, kiosk cameras. They produce high-resolution images but are sensitive to lighting conditions and are the easiest to spoof, since a photo or screen can simulate the same visual output a real face produces.
Near-infrared (NIR) cameras capture reflected infrared light, which makes them insensitive to visible ambient light and more consistent across different environments. Critically, NIR also reveals properties of real skin tissue (subsurface scattering from blood and melanin) that printed photos and screens do not replicate well, making them more robust to print-based spoofing. Apple’s Face ID infrared camera enables recognition in complete darkness and rejects most 2D photo attacks.
Depth sensors generate a three-dimensional map of the scene. Apple’s TrueDepth system projects 30,000 infrared dots onto the face using a structured light projector; the IR camera captures the distortion pattern of those dots as they fall on the face’s 3D surface, and depth is reconstructed from dot displacement. Google’s newer Pixel hardware uses a time-of-flight sensor instead. Both approaches produce a 3D point cloud of the face that makes flat-surface spoofing effectively impossible: a printed photo produces no depth variation; a real face produces a distinctive 3D contour.
High-security deployments often fuse multiple modalities. Face ID combines the structured light depth sensor with the NIR camera simultaneously, requiring a match in both 3D shape and 2D infrared texture. Software-only systems using standard RGB cameras provide the lowest level of inherent spoofing resistance and depend entirely on algorithmic liveness detection to compensate.
Capturing the face
Most production systems capture short video clips rather than a single image, because multiple frames provide more information, allow the system to select the highest-quality frame, and enable motion analysis for liveness. Typical capture windows are 1 to 5 seconds of video at 30 fps. The system then applies frame selection logic using quality metrics before passing any frame to the detection model:
- Blur score: measured via Laplacian variance or similar; frames with motion blur or out-of-focus faces are discarded.
- Face size and centering: the face bounding box must be large enough to contain sufficient detail for the embedding model and approximately centered in the frame.
- Facial landmark confidence: detected landmark positions (eyes, nose, mouth corners) must meet confidence thresholds; low-confidence detections indicate partial occlusion or extreme pose.
- Lighting uniformity: extreme overexposure or underexposure degrades embedding quality; histogram analysis filters frames outside an acceptable range.
User guidance prompts — “move closer,” “improve your lighting,” “look directly at the camera” — are the system’s mechanism for steering the user toward frames that will pass quality gates. They are not cosmetic; they are feedback loops driven by the real-time quality measurement.
Face detection
Detection determines whether a face is present and where it is in the frame. Modern face detectors — MTCNN, RetinaFace, SCRFD, and variants — use convolutional neural networks to generate bounding boxes and facial landmark predictions simultaneously. They are trained to handle partial occlusions (glasses, masks, hats), extreme poses, and multiple faces in a single frame. When multiple faces are found, the system applies selection rules: largest face, most centered face, or face closest to the depth sensor.
Alignment and normalization
A detected face bounding box is not sufficient for reliable embedding. Different people present their faces at different angles, distances, and orientations. Alignment removes this variability by identifying five key facial landmarks (left eye center, right eye center, nose tip, left mouth corner, right mouth corner) and applying a similarity transform to produce a canonical representation where landmarks fall in fixed positions. The result is a “face chip” — typically a 112×112 pixel image of the face with consistent landmark positions, regardless of original image orientation. Most modern embedding models are trained on these 112×112 aligned chips and expect them as input.
Enrollment and Biometric Template Storage
The pipeline described above runs at verification time: a live image comes in and is compared against something stored. But the article so far has not addressed where that stored reference comes from or how it is protected. Enrollment — the process of registering a person’s face in the system — is where the biometric identity is established, and the quality of enrollment directly determines the long-term accuracy of the system.
The enrollment session
Enrollment typically applies stricter quality requirements than verification. The stakes are higher: a bad enrollment template creates a permanently degraded experience for that user, causing false rejections on every future authentication. A common enrollment design:
- Capture multiple frames (typically 5–15) across a controlled range of head poses and expressions: frontal, slight left rotation, slight right rotation, looking slightly up and down.
- Apply quality gating to each capture independently. Any frame that fails the quality metrics (blur, size, landmark confidence, lighting) is discarded and recaptured rather than used.
- Generate an embedding from each accepted frame.
- Store the complete set of per-frame embeddings as the enrolled template, or compute a representative template by averaging or clustering the embeddings.
Storing multiple enrollment embeddings at different poses and lighting conditions rather than a single embedding significantly improves match accuracy at verification time. The verification embedding is compared against all enrolled embeddings, and the highest similarity score is used for the match decision. This allows the system to succeed even when the verification image does not closely match the angle of any single enrollment frame.
Template aging and update
Human faces change over time — weight, age, hair, glasses, skin tone, facial hair. An enrollment template that was accurate at account creation degrades in accuracy over months and years. Production systems address this through template aging compensation: after a successful high-confidence verification, the system updates the enrolled template by adding the new embedding to the enrollment set (and optionally removing the oldest entry). The template gradually tracks the natural evolution of the user’s appearance without requiring an explicit re-enrollment event. The confidence threshold for triggering an update is typically higher than the verification threshold, to prevent low-quality or borderline matches from corrupting the stored template.
Biometric template storage and protection
Face embeddings are sensitive biometric data even though they are not images. They cannot be used to reconstruct a photograph of the face, but they uniquely identify an individual and cannot be changed if compromised — unlike a password or a phone number, a face is permanent. This gives biometric template storage a different risk profile from other credential types.
Legal frameworks reflect this. In the United States, Illinois’ Biometric Information Privacy Act (BIPA) requires explicit written consent before collecting, storing, or sharing biometric identifiers, including facial geometry scans and derived mathematical representations. EU GDPR classifies biometric data used for identification as special category data under Article 9, requiring explicit consent and stricter processing controls than ordinary personal data. Several US states passed BIPA-equivalent laws between 2022 and 2025. Non-compliance has produced some of the largest class-action settlements in tech: Illinois BIPA litigation against Facebook resulted in a $650M settlement; Google paid $100M for Google Photos facial recognition in Illinois.
Technical approaches to template protection try to produce stored representations that retain matching utility while reducing the risk that a compromised template can be used to reconstruct or replay the original biometric:
- Revocable (cancelable) biometrics: a user-specific transformation is applied to the raw embedding before storage, producing a transformed template. The original embedding is discarded. If the stored template is compromised, the transformation key can be changed and a new transformed template generated from a fresh enrollment, effectively “revoking” the old one without requiring the user to change their face. This is the closest analog to password rotation in the biometric domain.
- Template separation: the embedding is stored separately from the user identifier, with the linking information held in a separate access-controlled system. An attacker who compromises the embedding store cannot map embeddings back to individuals without also compromising the linking database.
- On-device storage: for consumer authentication (Face ID, Windows Hello), the enrolled template is stored only on the device in a secure enclave and never uploaded to a server. Matching happens entirely on-device. This eliminates server-side template breach risk at the cost of portability — the enrolled template does not follow the user to new devices.
A complete verification flow
With enrollment established, a verification attempt traces through the pipeline as follows:
- The user presents their face to the camera. The capture module selects the highest-quality frame from a short video clip using blur score, face size, and landmark confidence.
- The face detector identifies the bounding box and five key landmarks. A similarity transform produces a 112×112 aligned face chip.
- Liveness detection runs in parallel: passive analysis checks for rPPG signal, skin texture properties, and micro-expression patterns across the video clip. If active liveness is configured, the prompted challenge response is verified separately.
- If liveness is established, the aligned face chip enters the embedding model. A 512-dimensional L2-normalized embedding is computed.
- The live embedding is compared against all enrolled templates for the claimed identity. The maximum cosine similarity score is recorded.
- The match score is combined with contextual signals — device attestation, session risk, geographic consistency — and evaluated against the deployment threshold. Access is granted, a second factor requested, or the attempt denied.
- If the match is granted at high confidence, template aging logic may update the enrolled set with the new embedding to track natural appearance change over time.
Step 3 is the critical gate: liveness detection must occur before the embedding comparison, because the recognition model cannot distinguish a live face from a high-quality synthetic one. If an injected or synthesized input reaches step 4 without being caught at step 3, the recognition pipeline has no further mechanism to detect it.
Face Embeddings — Turning Faces into Numbers
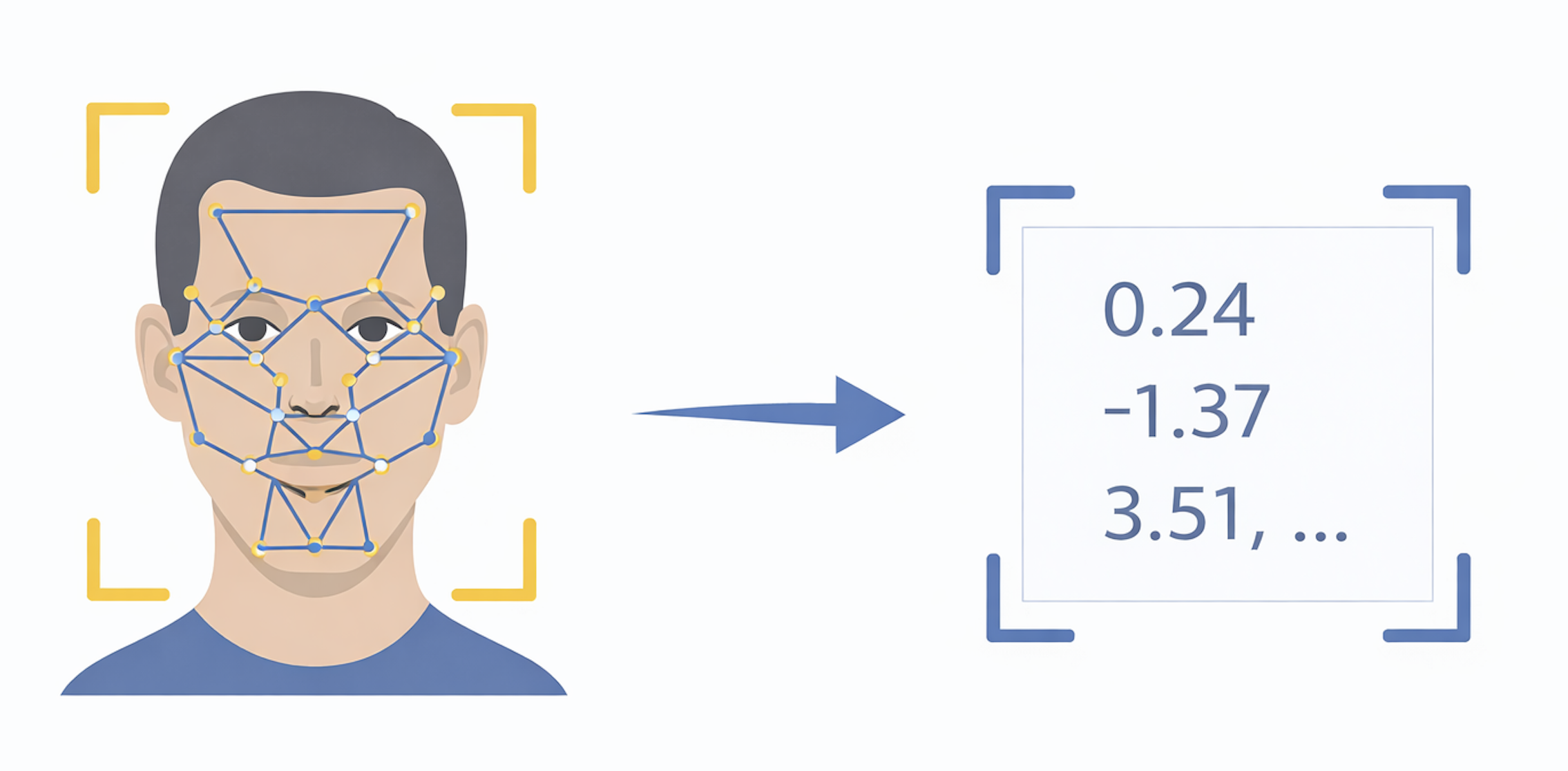
Once a face has been detected, aligned, and normalized to a 112×112 face chip, the system passes it through a neural network that converts it into a compact numerical vector called a face embedding. This is the step that makes modern facial recognition fundamentally different from earlier handcrafted approaches and that enables the accuracy levels production systems achieve today.
The embedding does not look like a face and is not interpretable by humans. There is no single number that corresponds to “nose shape” or “eye spacing.” Identity is encoded across all dimensions simultaneously. The network has learned, from millions of labeled face images, to emphasize features that are stable across lighting, pose, and expression while suppressing irrelevant variation. Photos of the same person taken under different conditions produce embeddings that are close together in the embedding space; photos of different people produce embeddings that are far apart.
Model architecture
Modern face recognition backbones use ResNet-50, ResNet-100, or ViT (Vision Transformer) architectures as the feature extractor. For a standard ResNet-100 face recognition model, the 112×112 face chip is processed through residual convolutional blocks that progressively extract higher-level features, from low-level edge and texture patterns in early layers to abstract structural patterns representing face shape and topology in later layers. The final feature vector is then projected to a fixed-length output — typically 512 dimensions — chosen as the practical optimum between expressiveness and efficiency. Larger embeddings capture incrementally more identity information; the returns diminish significantly above 512 dimensions while storage and computation costs grow linearly.
The 512-dimensional embedding is then L2-normalized: divided by its own magnitude so that it becomes a unit vector sitting on a 512-dimensional hypersphere with radius 1. This normalization has an important consequence: all embeddings are now at the same “distance” from the origin, and measuring the angle between two embeddings (cosine similarity) becomes equivalent to computing their Euclidean distance. Thresholds applied to cosine similarity are therefore stable and transferable between different databases and scales, unlike raw Euclidean distances that depend on the magnitude of the vectors.
Training objectives: from triplet loss to ArcFace
The quality of the embedding space depends critically on the training objective — the loss function used to train the network. The history of face recognition model training is largely a story of improving loss functions.
Triplet loss (FaceNet, 2015) operates on triples of images: an anchor, a positive example (same person as anchor), and a negative example (different person). The loss penalizes the network when the anchor-positive distance exceeds the anchor-negative distance by less than a margin. Training on triplets directly optimizes the embedding space for same-person similarity and different-person separation, which is exactly the property needed for face recognition. The limitation is training instability: the quality of the gradient depends heavily on which triplets are mined, and mining hard negatives at scale is expensive. FaceNet achieved strong results for its time but required an enormous dataset (200M images) to do so.
Softmax-based approaches replaced triplet loss in practice. The network is trained as a closed-set classifier: given N identities in the training set, the last layer maps the 512D embedding to N class scores, and standard cross-entropy loss is minimized. This is much more training-stable than triplet mining. The embedding space produced by softmax training generalizes reasonably well to unseen identities at test time, even though the network was only trained to classify its N training identities. However, standard softmax does not explicitly enforce any geometric margin between class centers, leaving the embedding space less discriminative than it could be.
ArcFace (2019, CVPR) is the training objective that defines the current state of the art. It operates in the angular space of the L2-normalized embedding. After normalization, the angle between an embedding vector and a class weight vector (the “class center”) measures how closely the embedding matches that identity. ArcFace adds an additive angular margin m to the target class angle before computing the softmax. Effectively, to correctly classify a face as belonging to identity yi, the embedding must not just be closer to identity yi’s class center than all others — it must be closer by at least m angular degrees. This margin constraint forces the network to push same-identity embeddings tightly around each class center while pushing different-identity class centers far apart on the hypersphere. The result is an embedding space with significantly better intra-class compactness and inter-class separability than softmax alone, without the training instability of triplet loss.
AdaFace (2022, CVPR) extends ArcFace by making the margin adaptive based on image quality. High-quality images receive a larger margin penalty — the model is pushed harder on clear, well-lit faces. Low-quality images receive a smaller margin, because penalizing the model for failing to correctly place a blurry, extreme-angle, or poorly lit face embedding is counterproductive. This quality-adaptive margin significantly improves performance on in-the-wild images and real-world deployment scenarios where input quality is variable. AdaFace is currently the state of the art for unconstrained face recognition benchmarks.
Similarity & Matching
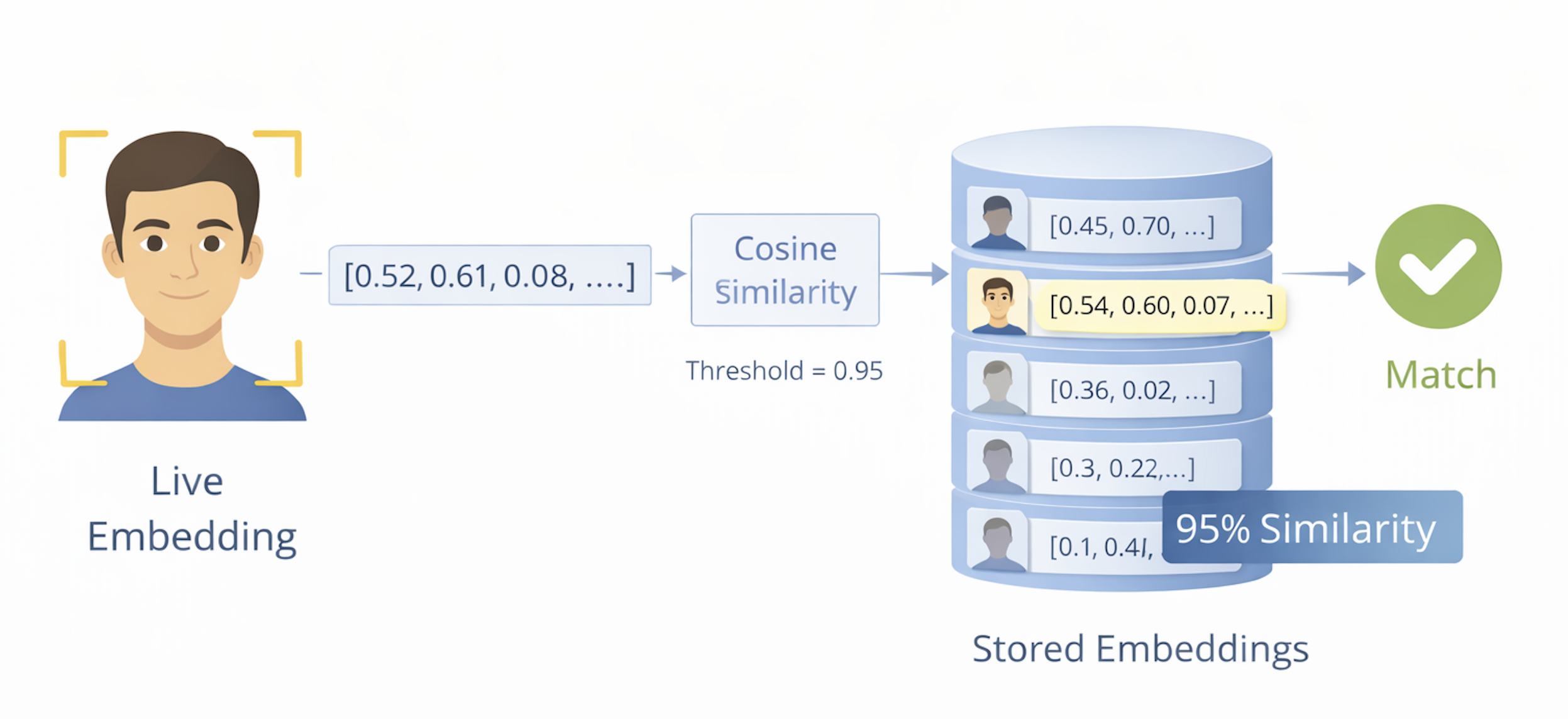
Once a live embedding has been generated and enrolled templates exist, recognition becomes a geometric problem: measure the distance between the new embedding and the stored templates, then decide what that distance means. This step combines mathematics with policy in ways that have direct security consequences.
Distance metrics
Because all embeddings are L2-normalized to unit length, two distance metrics produce equivalent rankings: cosine similarity (the dot product of two unit vectors, ranging from −1 to 1, where 1 means identical direction) and Euclidean distance (the straight-line distance between two points on the unit hypersphere). Cosine similarity is more commonly used in reporting — it is intuitive, with higher scores meaning more similar faces — while Euclidean distance is equivalent after normalization and is used in ANN (approximate nearest neighbor) search libraries like FAISS for large-scale identification.
When a user has multiple enrolled templates, the system computes similarity between the live embedding and each enrolled template and uses the maximum similarity score for the match decision. This is the standard approach because it selects the enrolled template that most closely matches the current presentation, maximizing the probability of a correct match while the minimum-score alternative would be excessively strict.
Large-scale 1:N identification and ANN indexing
The discussion above assumes 1:1 verification: comparing a live embedding against enrolled templates for a single claimed identity. Many applications require 1:N identification: finding the closest match across an entire gallery of enrolled identities without a prior identity claim. Watchlist screening, de-duplication during onboarding, and physical access systems without identity cards all require this mode.
At small gallery sizes, exhaustive comparison is feasible. At millions of enrolled embeddings, exact nearest neighbor search becomes too slow for interactive applications. Approximate Nearest Neighbor (ANN) search indexes embeddings into structures that return the most similar entry much faster, at a small, configurable accuracy cost. Two approaches dominate production deployments:
- IVF (Inverted File Index, FAISS): partitions the embedding space into clusters using k-means. At query time, only the embeddings in the nearest clusters are searched exhaustively. Search time scales with cluster coverage rather than gallery size.
- HNSW (Hierarchical Navigable Small World): builds a multilayer graph where each node connects to its nearest neighbors. Search descends from sparse upper layers to progressively denser layers, converging on the nearest neighbor efficiently. HNSW offers high recall at low latency and handles frequent updates well.
The security consequence is that 1:N identification has a different error profile from 1:1 verification. The probability that the closest non-matching entry is spuriously similar to the probe increases with gallery size. Thresholds calibrated on small galleries must be recalibrated as the enrolled population grows, or false acceptance rates will rise with scale in a way that point-in-time testing does not reveal.
FAR, FRR, and the EER
Any threshold creates two error rates that move in opposite directions as the threshold changes:
- False Acceptance Rate (FAR): the fraction of impostor attempts (different people claiming to be a specific user) that are incorrectly accepted. FAR decreases as the threshold becomes stricter.
- False Rejection Rate (FRR): the fraction of genuine user attempts that are incorrectly rejected. FRR increases as the threshold becomes stricter.
The relationship between FAR and FRR is captured by a Detection Error Tradeoff (DET) curve: a plot of FRR against FAR across all possible threshold values. Every point on the curve represents a different operating point with a different security-usability balance. The Equal Error Rate (EER) is the point on this curve where FAR equals FRR; it serves as a single-number summary of system accuracy independent of any particular operating threshold. State-of-the-art face recognition systems achieve EERs below 0.1% on standard benchmarks like LFW and IJB-C, though real-world performance depends heavily on image quality and demographic diversity in the training data.
Threshold tuning for different contexts
Choosing the operating threshold is not a technical decision — it is a policy decision that reflects the specific risk tolerance of the deployment context. The same underlying model might be deployed at very different thresholds depending on use case:
- Phone unlock: convenience is high priority. A FAR of 1 in 1,000,000 (Apple Face ID’s stated figure for strangers) is acceptable; the benefit of seamless unlock for the legitimate owner outweighs the risk of an attacker with a similar-looking face occasionally unlocking a device. FRR of 1–2% is tolerable — the user can enter a PIN.
- Financial services identity proofing: regulatory compliance requires strict control of false acceptances. A FAR of 1 in 10,000 or lower is required; FRR of 5–10% is acceptable since a rejected application can be reviewed manually. Some jurisdictions mandate specific FAR thresholds by regulation.
- Border control and high-security access: FAR must be as low as possible regardless of impact on FRR; operational security requires that only verified individuals enter. High FRR is acceptable and managed through secondary inspection lanes.
Demographic accuracy disparities
Face recognition systems do not perform uniformly across all demographic groups, and this differential accuracy has direct consequences for any organization deploying facial verification at scale. The NIST Face Recognition Vendor Testing (FRVT) program — the most rigorous independent benchmark of commercial systems — has documented that false match rates and false non-match rates vary significantly across dimensions of skin tone, age, and sex, with the most pronounced disparities typically affecting darker-skinned females. In FRVT evaluations, false match rates at a fixed threshold have varied by a factor of up to 100 across demographic groups for the same algorithm: a threshold calibrated to achieve 1 in 100,000 false acceptances for one demographic segment may produce 1 in 1,000 for another.
The root causes are compound. Training datasets have historically overrepresented lighter-skinned faces, because widely available labeled datasets skewed toward celebrity imagery and social media populations that did not reflect real-world demographic diversity. Models trained on these datasets perform best where their training data was densest. Lighting conditions interact with skin tone in ways that amplify this effect: under-lit environments reduce facial texture signal more severely for darker skin tones, while direct overhead illumination can wash out detail in lighter ones. Liveness detection models show separate demographic accuracy disparities from recognition models, meaning the overall system error compounds two distinct sources of differential performance.
The practical implications depend on context. In consumer phone unlock, differential FRR means some users are rejected by their own device at higher rates — a usability asymmetry. In financial services identity proofing, differential FRR means some customer populations are routed to manual review more often than others — a compliance and fairness issue that regulators in the EU (under AI Act provisions for high-risk biometric systems) and several US states are beginning to scrutinize explicitly. Systems designed for regulated deployment should require testing across the specific demographic distribution they will serve, using NIST FRVT data as a baseline but not a substitute for in-distribution evaluation before launch.
Context shapes the final decision
Production systems rarely rely on the face similarity score alone. The matching score is combined with contextual signals before a final access decision is made: whether the request originates from a trusted, enrolled device; the user’s geographic location and whether it is consistent with recent activity; whether behavioral patterns look normal; and the output of the risk engine. If the face match is strong but the context looks anomalous — an unfamiliar IP, a recently flagged account — the system may require a second factor. If the face match is borderline but every other signal is low-risk, the system may accept the authentication. Facial recognition is one input to an identity decision, not the sole authority.
Liveness Detection

The pipeline described so far can be fooled by a photograph. If the recognition model is given an aligned, well-lit image of someone’s face — captured from a social media profile, a company directory, or a personal photo — it will generate an embedding that matches the enrolled template. Recognition answers “is this the same face?” It does not answer “is this a real, physically present person?” That is liveness detection’s job.
Liveness detection sits as a parallel check alongside the recognition pipeline, typically applied after face detection but before a final match is accepted. If liveness cannot be established, the system refuses to proceed regardless of the similarity score.
Active vs. passive liveness
Active liveness requires the user to perform a prompted action: blink, smile, turn the head left then right, follow a moving target, or type a number displayed on screen. The system verifies that the action was performed correctly in real time. The key security property is unpredictability: because the challenge is generated randomly per session, a pre-recorded video that happens to contain a blink cannot reliably satisfy a challenge that also requires a specific head turn at a specific time. Active liveness is more robust against replay attacks but adds friction — users must actively participate rather than simply looking at the camera.
Passive liveness analyzes one or more frames of video without requiring any user interaction. The system looks for properties of real faces that printed photos, screens, and non-living artifacts cannot reproduce: subtle micro-expressions, involuntary eye movements, skin texture properties under different color channels, and physiological signals like the photoplethysmographic (rPPG) pulse signal visible in color variation across the skin. Passive liveness is seamless from the user’s perspective — the camera simply captures a brief clip — but it has historically been easier to attack than active liveness because the challenge is implicit and the attack surface is the model’s ability to detect artificiality rather than verifying a specific action.
Production systems increasingly use hybrid approaches: passive analysis runs continuously throughout a session to establish a baseline, and active challenges are triggered when passive scores fall below a confidence threshold.
Hardware liveness: Apple Face ID
Apple Face ID is the most widely deployed hardware-backed liveness system. Its TrueDepth camera module combines three components: a structured light infrared dot projector, an infrared flood illuminator, and a near-infrared camera. During authentication, the IR projector fires a pattern of 30,000 dots onto the face; the IR camera captures the dot pattern as distorted by the face’s three-dimensional surface; a dedicated neural engine reconstructs a depth map from the dot displacement. The depth map is compared against the enrolled 3D face model simultaneously with the IR appearance. A flat surface produces no depth variation; a 3D printed face produces a depth map but no matching IR texture; a silicone mask might produce a depth map but fails the texture comparison. Face ID also requires gaze attention (the eyes must be open and directed at the device) which defeats attempts using a photo of a sleeping or unconscious person. Apple states that the probability of a random face unlocking Face ID is 1 in 1,000,000, versus 1 in 50,000 for Touch ID.
ISO 30107-3: the presentation attack detection standard
The international standard for evaluating liveness detection is ISO/IEC 30107-3, which defines the testing methodology for Presentation Attack Detection (PAD) systems. It establishes a taxonomy of attack types:
- 2D attacks: print attacks (photo printed on paper or displayed on screen), video replay attacks (pre-recorded video of the target).
- 3D attacks: silicone masks, 3D-printed faces, rigid masks, flexible wearable masks.
- Partial attacks: eye region cut-outs used to pass gaze detection while displaying a photo.
The standard defines two error metrics: APCER (Attack Presentation Classification Error Rate — what fraction of attack presentations are incorrectly accepted as genuine) and BPCER (Bona Fide Presentation Classification Error Rate — what fraction of genuine users are incorrectly rejected as attacks). Systems are evaluated at specific BPCER operating points (e.g., APCER at BPCER=0.01) to compare PAD performance across vendors. ISO 30107-3 compliance has become a procurement requirement for identity verification in financial services and government identity programs.
Injection attacks: the dominant attack vector
ISO 30107-3, active liveness, passive liveness, and even hardware sensors like depth cameras all share one critical assumption: the image data reaching the analysis software came from a real, physical camera sensor. Injection attacks invalidate this assumption, and they have become the primary attack vector against production identity verification systems.
In an injection attack, the attacker does not present a physical artifact to the camera at all. Instead, they inject a synthetic video stream directly into the operating system’s camera interface, bypassing the physical sensor entirely. Operating systems expose camera access through standardized APIs: DirectShow on Windows, AVFoundation on macOS and iOS, V4L2 on Linux, Camera2 on Android. Virtual camera drivers — OBS Virtual Camera, ManyCam, and custom drivers — can register as legitimate camera devices at the OS level. Applications that access the camera through the standard API cannot distinguish between a real physical sensor and a virtual camera source registered at the same API layer.
When the identity verification application opens the camera and begins capturing frames, it receives frames from the virtual camera driver, which is sourcing them from a pre-recorded video, a real-time deepfake pipeline, or a static image playback loop. All software-based liveness analysis — blink detection, head turn verification, passive texture analysis — operates on the injected stream. If the injected content is designed to contain the prompted actions (a pre-recorded video of the target blinking and turning their head), active liveness challenges can be defeated. If the injected content is a well-crafted deepfake, even sophisticated passive liveness models may fail.
Injection attacks require no physical proximity to the target, no printed photos, no physical masks. They require a valid ID document of the target (or a synthetic identity), a deepfake generation tool (available for under $50/month commercially), a virtual camera driver (freely available), and a captured or synthesized video of the target. The technical barrier is significantly lower than for physical artifact attacks.
Defense against injection attacks requires controls that operate at a different level than liveness analysis:
- Device attestation: Apple Device Check and Google Play Integrity API verify that the application is a genuine, unmodified build running on a non-compromised device. This does not directly prevent injection but prevents attacks on rooted or jailbroken devices where camera APIs are most easily intercepted. Attestation also confirms the app build hasn’t been tampered with to bypass security checks.
- Sensor metadata analysis: real camera sensors have characteristic noise signatures — fixed pattern noise from sensor imperfections, temporal readout noise, lens distortion specific to the optical system, and dead pixel patterns unique to individual sensors. Synthetic video streams either lack these signatures or have statistically uniform noise that does not match the sensor profile. Comparing the noise characteristics of incoming frames against the expected sensor profile can detect virtual camera injection with high confidence.
- OS-level camera source verification: iOS 17 and later provides camera device metadata through AVFoundation that includes whether the camera source is a physical sensor or a virtual device. Applications can reject virtual camera sources at the API level. This defense is available on iOS but equivalent controls are less mature on Android and Windows.
- Challenge-response over secure channel: some systems generate a cryptographic challenge that must be included as a steganographic watermark in the captured video stream, which only the genuine application running on the device can produce. Pre-recorded injection content cannot satisfy this challenge.
Deepfakes — A Rapidly Escalating Spoofing Risk
Traditional spoofing attacks rely on physical artifacts: printed photos, screens displaying videos, silicone masks. Deepfakes are synthetic media that replaces or augments a real face using generative AI, producing imagery that can be realistic enough to deceive both human reviewers and automated detection systems. Combined with injection attacks, deepfakes have become the primary technique in sophisticated identity fraud targeting biometric verification systems.
The scale of the problem in 2024–2026
The numbers from recent years illustrate how quickly this threat has escalated. Onfido’s 2023 fraud report documented a 3,000% increase in deepfake attempts against their identity verification platform year-over-year. Sumsub reported a 245% increase in deepfake fraud attempts in financial services in 2024. Deepfake-enabled fraud losses reached approximately $1.1 billion in the United States alone in 2025, triple the prior year. Voice deepfakes — often deployed alongside facial deepfakes in coordinated attacks — increased 680% year-over-year in 2025. By 2025, 37% of organizations globally had experienced deepfake-related fraud, per EY survey data.
The most significant individual case is the February 2024 Arup incident: employees at the Hong Kong engineering firm authorized wire transfers totaling $25.6 million after participating in a video conference call that included what appeared to be the company’s CFO and several colleagues. Every participant in the call except the victim was AI-generated — real-time deepfakes driving avatars animated to match the voices. No single frame of the video clearly indicated synthetic generation. The employees only realized they had been defrauded after calling the CFO through a separate channel. This case demonstrated that deepfake attacks had advanced beyond still images and pre-recorded videos to real-time video generation convincing enough to deceive humans in an interactive context.
Generation methods: GAN-based face swap vs. diffusion-based synthesis
Deepfakes are not a single technology; the term covers several distinct generation methods with different characteristics and different detection signatures:
GAN-based face swap (DeepFaceLab, FaceSwap) replaces one person’s face in a video with another’s while preserving the original video’s motion, lighting, and head tracking. The target identity’s face is extracted from training images, a GAN is trained to map their facial appearance onto the source video, and the result is composited back into the original footage. Face swap inherits the natural motion from a real video source, making temporal analysis more difficult. GAN upsampling processes leave characteristic spectral artifacts — grid-like patterns visible in the high-frequency components of the DCT or FFT transform — that trained detectors can identify. Detection accuracy against GAN-based content is relatively high on the generation architectures detectors were trained against.
Diffusion-based face synthesis generates a photorealistic face de novo from noise, guided by text prompts, reference images, or motion sequences. Models like AnimateDiff, LivePortrait, and EMO (Alibaba DAMO) drive a synthesized face with motion derived from a driving video or audio waveform. The generated face never existed as a real person; there is no source video to trace. Diffusion-generated content has a different artifact distribution than GAN-generated content — detectors trained on GAN artifacts often fail badly against diffusion-generated deepfakes, because the artifacts they learned to identify are absent. The quality ceiling of diffusion synthesis improves with each generation of models, reducing the reliability of artifact-based detection approaches over time.
Real-time face replacement in video calls (DeepFaceLive, several commercial products) performs face swap at the frame rate of a live video stream with 100–200ms of added latency. This latency is typically within the range of normal video call network delay and is not perceptible to the other participants. These tools commonly run as virtual camera drivers, directly connecting the deepfake pipeline to the injection attack vector described in the previous section.
Accessibility
A significant factor in the escalation of deepfake fraud is the accessibility of generation tools. Commercial services including HeyGen, Wondershare Filmora, and D-ID can produce convincing face-swapped or avatar-based video for under $50/month with no machine learning knowledge required. Open-source tools like DeepFaceLab and FaceSwap are freely available with community tutorials. The technical barrier to performing a deepfake-based identity fraud attack is now comparable to the barrier to performing a phishing attack — it requires motivation, a target, and commodity software, not specialized AI expertise.
Detection techniques
Multiple detection approaches have been developed, each with different strengths and failure modes:
Frequency domain analysis: GAN upsampling operations leave systematic patterns in the high-frequency components of the image that are visible when the image is transformed to the frequency domain (DCT or FFT). These “GAN fingerprints” can be detected reliably by classifiers trained on GAN-generated content. This approach is less effective against diffusion-generated content, which does not produce the same artifacts.
Temporal consistency analysis: real video has physics-constrained motion; optical flow between consecutive frames follows predictable patterns derived from physical motion of the face and the camera. Synthetic video produced by driving a face model with motion transfer has subtly different inter-frame statistics that can be detected by models trained on temporal inconsistency signals. This approach generalizes better across generation methods than frequency domain analysis.
Remote photoplethysmography (rPPG): living skin exhibits subtle periodic color changes synchronized with the cardiac cycle — blood volume changes as the heart beats cause hemoglobin to absorb and reflect light differently across different phases. This signal is measurable from video of exposed skin (forehead, cheeks) using color channel analysis. Synthesized faces do not reproduce this physiological signal faithfully. rPPG detection achieves strong results in controlled conditions but is sensitive to lighting variation and motion blur, which can obscure the subtle color signal in real-world captures.
Iris reflection analysis: real eyes reflect the environment consistently across both eyes; the reflections of light sources move in coordinated ways as the head rotates. Synthesized eyes frequently have inconsistent, non-physical reflections — light sources that appear in one eye but not the other, or reflections that do not move appropriately with head rotation. Iris reflection analysis is difficult to systematically fool and is effective against a range of generation methods.
Foundation model-based detection: Meta’s Detectron framework, trained on the Deepfake Detection Challenge (DFDC) dataset, demonstrated that large models trained on diverse deepfake sources generalize better across generation methods than smaller specialist detectors. However, all trained detectors face a fundamental generalization problem: they learn artifacts from the generation methods represented in their training data, and new generation architectures produce different artifact distributions that trained detectors may not recognize. This is the core limitation of the detection-side arms race.
The Persistent Arms Race
What the history of liveness detection and deepfake defense reveals is a pattern familiar from every security domain: offense and defense are coupled in a continuous escalation. Print attacks were defeated by video replay detection; video replay was defeated by active liveness challenges; active liveness was defeated by pre-recorded response video; pre-recorded video was defeated by randomized challenges and timing analysis; randomized challenges were defeated by real-time face reenactment; all of these were then bypassed by injection attacks that moved the attack surface below the software stack entirely.
No single detection technique ends this cycle. Systems that detect GAN artifacts are defeated by diffusion models. Systems trained on current deepfake methods are defeated by the next generation of generation architecture. This does not mean defense is futile — it means defense must be layered. The most resilient architectures combine hardware-level controls (trusted sensors, device attestation, OS-level camera source verification), algorithm-level controls (multiple independent liveness signals, rPPG, iris reflection), and signal-level controls (risk scoring on device, session, behavior, and network context). When any single layer is bypassed, the others provide independent resistance. No attack simultaneously defeats all of them with the same technique.
This architecture principle — defense in depth across independent control layers — is what distinguishes a facial verification system that can be defended from one that can be defeated by a single, increasingly accessible tool. The underlying identity decision is only as trustworthy as the weakest layer in the pipeline, which is why understanding each layer individually is the prerequisite for understanding the system as a whole.