
Try yourself: Create an account and login to an IdP at www.jchowlabs.me.
Identity Provider Internals
An identity provider is the control plane for how an organization manages identity at scale: who exists, how they authenticate, what they can access, and when that access should change or end. It sits at the center of every login event, every access decision, and every account lifecycle change across the enterprise. From the outside, it looks like a login screen. Under the hood, it is a collection of distinct subsystems — a directory, an authentication engine, a token issuance service, a federation gateway, a provisioning engine, and a conditional access layer — each solving a specific part of the identity problem, all tightly coupled.
This article walks through each of those components in detail, explains how they work individually and as a system, and covers the additions that have become essential to modern identity architecture: token lifecycle management, non-human identity, continuous access evaluation, signing key management, and identity threat detection. The goal is a complete, accurate mental model of how enterprise identity providers work beneath the surface — the kind of understanding that helps whether you are building against an IdP, securing one, or teaching how centralized identity actually functions.
Identity Provider Architecture
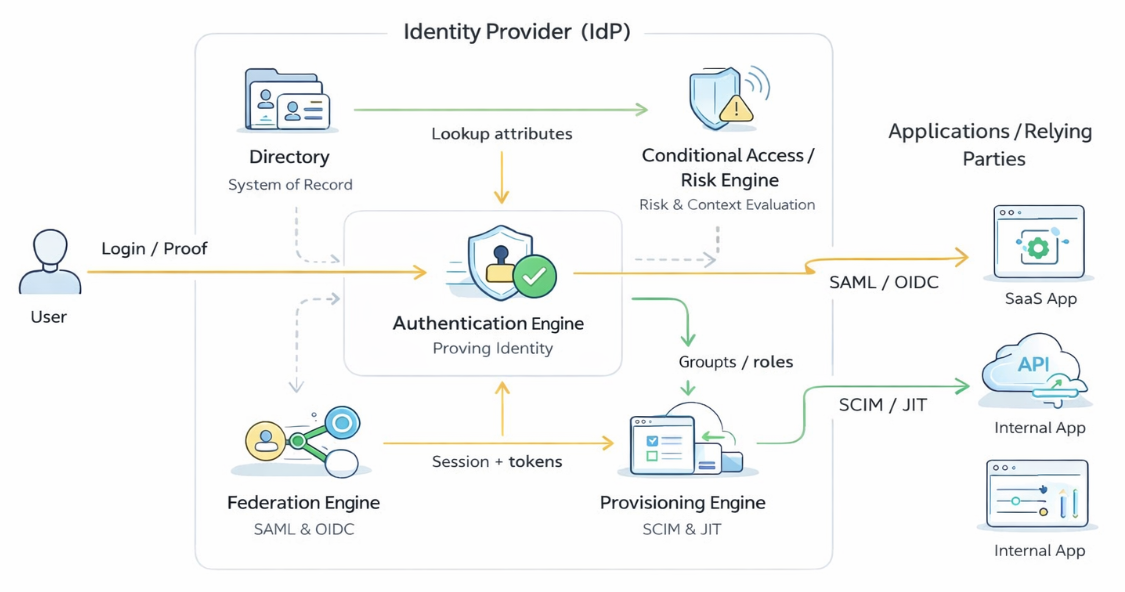
When you strip away vendor branding, most modern identity providers share a common conceptual architecture. They are not single-purpose tools but collections of cooperating components that together manage identity from creation through authentication, access enforcement, and eventual deprovisioning. Different products emphasize different capabilities, but a consistent pattern appears across cloud, hybrid, and on-premises systems.
At the core, an identity provider acts as an identity control plane rather than a simple login service. It coordinates several distinct functions that, taken together, allow organizations to know who someone is and what they should be able to do across many applications and systems.
The five primary components are:
- The directory — the system of record for who exists, what attributes they have, and how they are organized.
- The authentication engine — the orchestration layer that selects, sequences, and enforces methods of proving identity.
- The federation engine — the layer that translates a local authentication event into a portable, cryptographically protected identity statement that downstream applications can trust.
- The provisioning engine — the system that automatically creates, updates, and disables accounts in connected applications as identity changes.
- The conditional access engine — the policy and risk layer that evaluates context signals before allowing authentication to complete or continue.
Supporting these five are several infrastructure components that enable the system to operate correctly at scale: a token issuance service that generates signed OAuth 2.0, OIDC, and SAML credentials; a session store that maintains server-side session state; an audit and event log that records every authentication, authorization, and lifecycle event; JWKS and discovery metadata endpoints that allow relying parties to bootstrap trust and validate tokens without manual key exchange; and a management API that exposes administrative operations to operators and integrations.
In the sections that follow, we will examine each of the five primary components in depth, then cover token lifecycle, non-human identity, key management, and identity threat detection as distinct topics that cut across the whole architecture.
The Directory
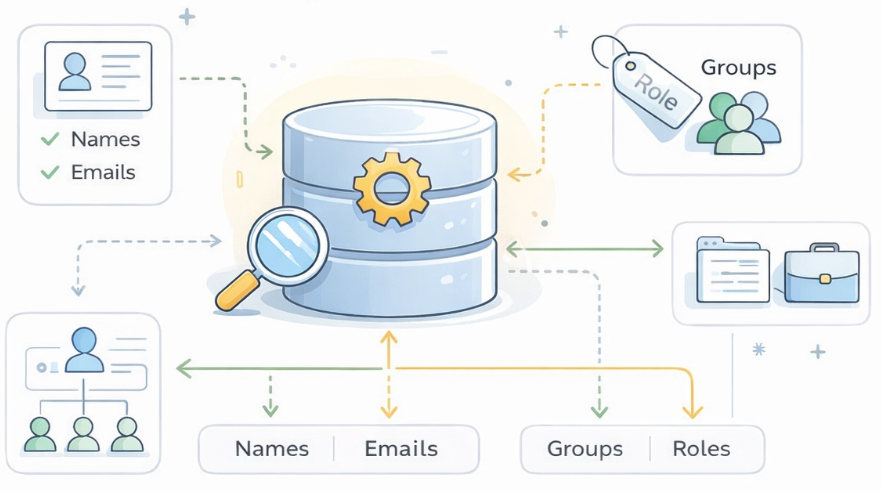
At the most fundamental level, every identity provider needs a place that answers a deceptively simple question: who exists? That place is the directory. Everything else in an identity system — authentication, federation, provisioning, and risk evaluation — ultimately depends on the directory being reliable, consistent, and current. If the directory is wrong, incomplete, or out of sync, the rest of the identity stack will behave unpredictably no matter how sophisticated it is.
In real-world deployments, identity providers take two common approaches to directories. Some organizations already have a well-established external directory — often Active Directory, LDAP, or a cloud HR system such as Workday or BambooHR — that serves as the primary system of record for employees and contractors. In those cases, the identity provider typically connects to and synchronizes with that external directory, ingesting users, groups, and attributes rather than replacing them. The identity provider does not own identity; it reflects and extends it, translating changes from the source into the rest of the application ecosystem.
Other organizations — especially cloud-native companies or greenfield environments — let the identity provider act as the directory itself. In this model, the identity provider is the authoritative source of truth for users and groups. Administrators create and manage identities directly inside the IdP, and all other systems treat it as the canonical record. For the purposes of this article, and for the concept of building your own identity provider, we assume this second model: your identity provider is also your directory.
A typical user record might include attributes such as:
- User ID — a stable, internal identifier that persists even if display names or emails change.
- First name and last name
- Email address — often the primary login identifier.
- Job title and department
- Manager — enables organizational hierarchy traversal.
- Employment status — active, on leave, or terminated.
- Start date and end date
- Roles and group memberships
- Location — office, region, or country.
- Device enrollment state — whether the user has a registered managed device.
- MFA enrollment — which authentication methods the user has registered.
Alongside individual users, most directories also maintain groups — “Engineering,” “Finance,” “Global Admins” — which serve as the primary organizing principle for access management. Rather than assigning permissions one person at a time, administrators reason about access in terms of teams and roles. Group membership drives provisioning decisions, conditional access policies, and the claims embedded in tokens issued to applications.
In more advanced environments, identity providers can connect to multiple external directories simultaneously — an HR system for employees, a separate directory for contractors, another for customers — and reconcile them into a unified identity view. Regardless of how many sources feed the directory, the identity provider maintains a coherent internal model that all downstream components depend on.
Non-human identities are increasingly a first-class concern in the directory. Service accounts, OAuth client applications, API credentials, machine identities, and AI agent identities all need a home in the directory alongside human users. In modern enterprise environments, non-human identities outnumber human identities by 50 to 100 to one, and this ratio is growing as AI adoption scales. Most traditional IdP directories were not designed with this scale of machine identity in mind; many organizations manage NHI in separate credential stores or secrets managers rather than through the same lifecycle machinery that governs human accounts. This is a significant gap, addressed further in the Non-Human Identity section below.
The directory is the backbone of the identity provider: simple in concept, but absolutely essential to everything that follows. Three core pieces summarize it:
- Users — who exists, including both human and non-human identities.
- Groups and roles — how identities are organized and what access they carry.
- Attributes and relationships — what distinguishes one identity from another and signals how they should be treated.
Authentication Engine
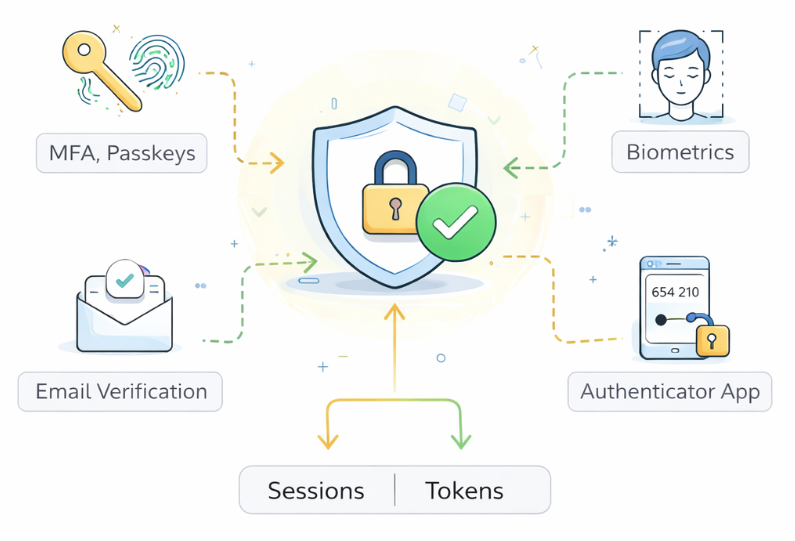
The authentication layer is responsible for verifying that a user is actually who they claim to be. Rather than a single check or a single technology, it is best understood as an orchestration engine that selects, sequences, and enforces different ways of proving identity depending on context and risk. Modern identity providers like Okta and Entra ID model authentication as a configurable flow graph — each step is a node, and policies determine which path a user follows based on their attributes, device, location, and the application they are accessing.
Most identity providers support multiple authentication methods because no single mechanism works equally well for every user, every device, and every risk context. Common methods include:
- Username and password — still common but increasingly treated as a baseline rather than a sufficient control. Password-based authentication is vulnerable to phishing, credential stuffing, and brute-force attacks.
- Multi-factor authentication (MFA) — a second factor added on top of the password. Common MFA types include: TOTP (time-based one-time passwords from an authenticator app), push notification approval, SMS OTP (weakest, vulnerable to SIM swapping), and hardware security keys.
- Passkeys (FIDO2 / WebAuthn) — cryptographic credentials that replace both password and second factor. Discussed in detail below.
- Smart cards and PIV credentials — hardware-backed certificates common in government and high-security enterprise environments.
- Biometrics — facial recognition or fingerprints, typically mediated through the user’s device operating system rather than the identity provider directly. The device validates the biometric and then releases the credential.
A known risk with push-based MFA is MFA fatigue, also called push bombing: attackers who have already stolen a user’s password repeatedly send push approval requests hoping the user accepts one out of confusion or frustration. Scattered Spider used this technique extensively in 2022–2023 to compromise major enterprises. Modern identity providers address this with number-matching (the user must enter a number shown in the app rather than just tapping approve) and additional context in push notifications.
Passkeys and FIDO2/WebAuthn
Passkeys are the most significant evolution in authentication methods in the past decade. Built on the FIDO2 standard — specifically the WebAuthn browser API and the CTAP (Client to Authenticator Protocol) — passkeys use public-key cryptography to replace passwords entirely.
When a user registers a passkey, the authenticator (the device’s Secure Enclave, TPM, or a hardware security key) generates an asymmetric key pair. The private key never leaves the authenticator. The public key is registered with the identity provider. Authentication works as a challenge-response: the IdP sends a random challenge, the device signs it with the private key, and the IdP verifies the signature with the registered public key. Because the private key never travels over the network, passkeys are immune to phishing, credential stuffing, and server-side credential breaches.
A critical security property of WebAuthn is origin binding: the key is cryptographically tied to the specific origin (the domain) for which it was created. A key created for example.com will not work on a lookalike site like examp1e.com, defeating even sophisticated phishing attacks that mimic legitimate sites.
Passkeys come in two forms:
- Device-bound passkeys — the private key is generated in and cannot leave a hardware security enclave. These are non-exportable and tied to a specific physical device. They provide the highest assurance but are inconvenient if the device is lost.
- Synced passkeys — the private key is encrypted and backed up through a cloud service (iCloud Keychain, Google Password Manager, Windows Hello with cloud backup). They work across a user’s devices linked to the same cloud account, offering better usability at slightly lower assurance than device-bound.
NIST SP 800-63-4 (finalized July 2025) formally recognizes synced passkeys as valid Authenticator Assurance Level 2 (AAL2) credentials, provided the sync service itself is protected by AAL2-equivalent controls. Device-bound phishing-resistant credentials are required for AAL3. The three assurance levels are:
- AAL1 — single-factor authentication. A password alone meets AAL1. Provides basic confidence in the authentication event.
- AAL2 — two-factor authentication. Requires proof of possession of a second factor alongside the password. Synced passkeys, TOTP, push MFA, and hardware keys all qualify. NIST SP 800-63-4 now requires IdPs to offer a phishing-resistant option at AAL2.
- AAL3 — hardware-bound phishing-resistant authentication. Requires a non-exportable cryptographic authenticator. Only device-bound FIDO2 credentials, PIV smart cards, or CAC cards qualify. Synced passkeys do not meet AAL3.
Enterprise passkey adoption is accelerating. As of 2025, 53% of users had enabled passkeys on at least one account, and 48% of the top 100 websites offered passkeys. Okta and Entra ID both support enterprise passkey policies including the ability to block synced passkeys on managed devices and enforce device-bound credentials for high-assurance flows.
Authentication flows
Authentication unfolds across several distinct flows that users experience over time.
Onboarding and enrollment is when the initial identity is established. The identity provider creates a user record, verifies email or phone ownership, and enrolls the first credential — ideally at a reasonably high assurance level. This is also when MFA methods and passkeys are first registered. The quality of this initial setup determines the strength of all subsequent authentications.
Day-to-day authentication is what most people think of as logging in. The authentication engine presents the appropriate method based on policy and context. A low-risk sign-in from a known managed device may require only a passkey or a password plus push MFA. A higher-risk sign-in from a new device or unusual location may require a stronger factor or additional verification.
The outcome of a successful authentication is not just “logged in.” The identity provider creates an authenticated session — a server-side record representing its current trust in the user. This session is the IdP’s memory that “this person has proven who they are and how strongly,” and it allows the user to move between applications without re-authenticating every few minutes. The session records the authentication methods used (captured as AMR — Authentication Methods References), the assurance level achieved, the time of authentication, and the last activity timestamp. In modern systems, this session state is stored in a low-latency store like Redis and is consulted by the conditional access engine and by CAEP transmitters when evaluating whether a session should be revoked.
Step-up authentication raises the requirement dynamically when the situation warrants it. A user who authenticated with a password and MFA in the morning may be required to perform a fresh phishing-resistant assertion before accessing a production cloud console or a payroll system later in the day. The authentication engine re-challenges without ending the existing session, records the upgraded assurance level, and allows the application to make its access decision based on the stronger authentication.
Account recovery is the highest-risk flow in the lifecycle. It is invoked under conditions of credential unavailability, often under urgency, and frequently reintroduces weaker verification channels that were deliberately excluded from primary authentication. Recovery flows are where social engineering is most effective and where attackers concentrate effort. Architecturally, recovery must impose at least as much verification burden as primary authentication — ideally more — and must produce comprehensive audit records for every event.
Token Lifecycle
When a user successfully authenticates through an identity provider, the result is not just a browser session. In modern OAuth 2.0 and OpenID Connect architectures, authentication produces a set of tokens — signed, time-limited credentials that carry identity claims and authorize access to applications and APIs. Understanding how tokens are structured, issued, validated, and revoked is essential to understanding how identity flows through a distributed system.
Token types
Three token types serve distinct roles in the OAuth 2.0 and OIDC ecosystem:
The access token is a credential presented by a client application to a resource server (an API or backend service) to prove that the client is authorized to make a request. Access tokens are typically short-lived — 5 to 60 minutes depending on sensitivity — because they are bearer credentials: whoever holds the token can use it. The resource server validates the access token and grants or denies the request based on the token’s claims and scopes. Access tokens are deliberately scoped to a specific set of permissions and are not meant to carry all user attributes.
The ID token is an OpenID Connect-specific credential intended for the client application, not the resource server. It contains claims about the authenticated user: who they are, when they authenticated, how they authenticated, and at what assurance level. The client uses the ID token to establish a local application session. ID tokens should never be sent to APIs as access credentials; that is the access token’s role.
The refresh token is a longer-lived credential used to obtain new access tokens without requiring the user to re-authenticate. Refresh tokens are kept confidential and stored securely — server-side in server-rendered applications, or in the operating system keychain or an HttpOnly cookie in native or browser applications. When an access token expires, the client presents the refresh token to the IdP’s token endpoint to receive a fresh access token. RFC 9700 (January 2025) mandates refresh token rotation for public clients: each use of a refresh token must return a new refresh token, and the old one must be immediately invalidated.
JWT structure
Most modern tokens are issued as JWTs (JSON Web Tokens): a compact, URL-safe format consisting of three base64url-encoded segments separated by dots: header.payload.signature.
The header identifies the signing algorithm (alg) and the key ID (kid). The kid tells the receiver which public key in the IdP’s JWKS to use for signature verification.
The payload carries the token’s claims. Standard claims include:
- iss — issuer, the IdP’s identifier.
- sub — subject, the user’s unique identifier.
- aud — audience, the intended recipient (the application or API).
- exp — expiration time, after which the token must not be accepted.
- iat — issued-at time.
- nbf — not-before time, the earliest the token is valid.
- jti — unique token identifier, used for replay prevention.
- amr — authentication methods references (e.g.,
pwd,mfa,hwkfor hardware key). - acr — authentication context class reference, corresponding to the NIST assurance level.
The signature is computed by the IdP using its private signing key. The receiver verifies the signature against the IdP’s public key (retrieved from the JWKS endpoint). A valid signature proves the token was issued by the trusted IdP and has not been tampered with since issuance.
PKCE
Proof Key for Code Exchange (PKCE, RFC 7636) prevents authorization code interception attacks. The authorization code flow involves the IdP redirecting the user’s browser to a callback URL with a short-lived authorization code. If an attacker intercepts this code, they could exchange it for tokens. PKCE prevents this by binding the code to a secret known only to the client.
The flow works as follows: the client generates a random code_verifier. It computes code_challenge = BASE64URL(SHA256(code_verifier)) and sends the code_challenge with the authorization request. When the client later exchanges the authorization code for tokens, it includes the original code_verifier. The IdP verifies that BASE64URL(SHA256(code_verifier)) matches the stored challenge before issuing tokens. An attacker who intercepts the authorization code but does not have the code_verifier cannot complete the exchange. RFC 9700 (January 2025) mandates PKCE for all OAuth 2.0 clients, not just public clients.
Sender-constrained tokens and DPoP
Standard bearer tokens are dangerous if stolen: whoever holds the token can use it. DPoP (Demonstrating Proof of Possession, RFC 9449) binds an access token to a specific client key pair so that the token is useless to an attacker who steals it without also stealing the client’s private key.
With DPoP, the client generates an asymmetric key pair and includes a signed DPoP proof JWT with every request to the token endpoint and resource server. This proof includes the HTTP method, URL, a timestamp, and a unique identifier. The IdP embeds the client’s public key thumbprint in the issued access token. The resource server verifies that both the DPoP proof and the token’s key binding are present and consistent. Okta, Auth0, and Entra ID all support DPoP as of 2024–2025. DPoP is particularly valuable for protecting tokens that travel across APIs and microservices where interception risk is higher.
Token introspection
When a resource server receives an opaque token (one that is not a self-contained JWT), or when it needs to know the current revocation status of a token rather than relying on expiration alone, it calls the IdP’s token introspection endpoint (RFC 7662). The resource server sends the token and receives back a JSON response containing whether the token is currently active, its associated claims, and its expiration time. If active: false, the token has been revoked or has expired, and the request should be denied.
Introspection adds latency since it requires a network call to the IdP on each validated request. Resource servers typically cache introspection results briefly, but must balance cache lifetime against the risk of accepting recently revoked tokens. In CAEP-integrated environments, cache invalidation can be triggered by a revocation signal, eliminating the staleness problem.
Token revocation
When a user logs out or a token is no longer needed, the client notifies the IdP via the token revocation endpoint (RFC 7009). The IdP immediately marks the token as revoked in its store. For refresh tokens, the IdP also revokes all access tokens issued from the same authorization grant.
The fundamental challenge is access token revocation propagation. Because access tokens are JWTs validated locally by resource servers without calling the IdP, a revoked access token continues to work at those resource servers until it expires naturally. If the access token lifetime is 60 minutes, a revoked token can still be used for up to 60 minutes after revocation. This is the core limitation that motivated Continuous Access Evaluation (CAEP), described in the Conditional Access section below.
Recommended token lifetimes
RFC 9700 (January 2025) consolidates OAuth 2.0 security best practices and recommends the following token lifetimes:
- Access tokens for sensitive APIs: 5–15 minutes.
- Access tokens for general APIs: 30–60 minutes.
- Refresh tokens: 7–30 days, with rotation on each use.
- SAML assertions: maximum 5 minutes to limit replay risk.
Shorter access token lifetimes reduce the blast radius of stolen tokens but increase the frequency of refresh token exchanges. The right balance depends on the sensitivity of the protected resource and the organization’s risk tolerance.
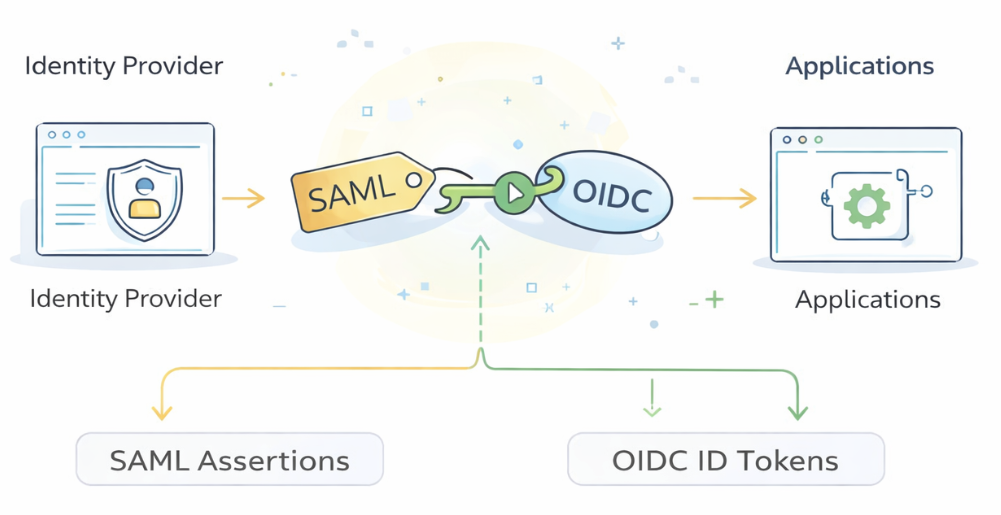
Federation Engine
While authentication determines whether a user is who they claim to be, federation determines which system gets to make that determination. Historically, most enterprise applications authenticated users in isolation — each system required its own username and password, maintained its own identity store, and independently decided whether to trust a user. At scale, this produced password sprawl: too many credentials, widespread reuse, frequent resets, and a large attack surface for phishing and credential theft.
Identity providers shift this model in a deeper way than simply making login easier. Instead of hundreds of applications independently authenticating users, organizations centralize that responsibility in one place. The identity provider becomes the trusted authority that verifies identity, and applications agree in advance to accept its judgment. From the user’s perspective this feels like single sign-on; from a security perspective it is a deliberate move from many isolated authentication silos to a network of trust anchored on a single identity system.
Federation is the set of standards that make this possible. A federation protocol defines how an identity provider can make a verifiable statement about a user, and how an application can safely rely on that statement instead of collecting credentials itself. In modern enterprise deployments, two standards dominate:
- SAML 2.0 (Security Assertion Markup Language) — an XML-based standard, deeply embedded in enterprise SaaS and legacy applications. Still widely deployed despite being over two decades old.
- OpenID Connect (OIDC) — a modern, web-native identity layer built on top of OAuth 2.0. Preferred for new applications, APIs, and mobile apps.
- WS-Federation — a SOAP-era standard that appears in legacy Microsoft-centric environments. Not used in new deployments; consider it effectively deprecated for greenfield work.
OAuth 2.0 is often mentioned alongside these but is primarily an authorization protocol — about what a client is permitted to do — not a federation protocol on its own. OpenID Connect is what adds the identity layer on top of OAuth 2.0.
How trust is established: registering applications with the IdP
Before any federation flow can work, a one-time setup step must occur: each application must be registered with the identity provider. This is how trust is bootstrapped. During registration, the application tells the IdP who it is, where authenticated users should be redirected after login, and what claims or scopes it needs. The IdP shares its public signing key or certificate so the application can verify token signatures. Nothing dynamic is happening at runtime — federation is built on pre-established trust relationships.
OpenID Connect relying parties discover endpoint locations and signing key information dynamically through the OpenID Connect Discovery document at /.well-known/openid-configuration. This JSON document, published at the IdP’s issuer base URL, contains the authorization endpoint, token endpoint, JWKS URI, supported grant types, supported scopes, and signing algorithms. A relying party that knows only the IdP’s issuer URL can retrieve this document and automatically configure itself — no manual endpoint entry required. This makes OIDC federation substantially more maintainable at scale than SAML, where metadata must typically be exchanged as static XML files and updated manually when signing certificates change. The discovery document is also how relying parties find the JWKS URL to retrieve signing keys, making it the entry point to the cryptographic trust chain rather than an optional convenience feature.
SAML flows
SAML is best understood as a language for delegated authentication. The identity provider authenticates the user and issues a signed XML document — the SAML assertion — that other applications agree to trust.
A SAML assertion contains:
- Who the user is (an email, UPN, or unique identifier)
- When they authenticated and by what method
- The assertion’s validity window (typically 5 minutes, to prevent replay)
- The intended audience (which application should accept this assertion)
- Attribute statements (roles, group memberships, or other claims)
The assertion is signed with the IdP’s private key. Applications validate the signature using the IdP’s public certificate configured during registration.
In SP-initiated SSO (the most common and secure flow), the sequence is:
- The user attempts to access a protected application. The application has no active session.
- The application generates a
SAMLRequest(anAuthnRequestXML document) and redirects the user’s browser to the IdP’s SSO endpoint, including aRelayStatevalue to restore state after login. - The IdP authenticates the user using its authentication engine, or uses an existing IdP session.
- The IdP generates a signed
SAMLResponsecontaining the assertion and POSTs it to the application’s Assertion Consumer Service (ACS) URL via a browser-submitted HTML form. - The application validates the signature, checks the audience, confirms the assertion is within its validity window, and verifies the
InResponseTofield matches the originalAuthnRequestID. - The application creates a local session and grants access.
In IdP-initiated SSO, the user starts at the IdP (for example, clicking an app tile in a company portal) and the IdP sends an unsolicited assertion — no AuthnRequest and no InResponseTo. This convenience comes with a security tradeoff: without an InResponseTo, the application cannot bind the assertion to a prior request, making it susceptible to certain CSRF and replay attacks. Modern OIDC applications reject unsolicited responses entirely. For SAML applications that must support IdP-initiated flows, additional anti-CSRF validation on RelayState is recommended.
OpenID Connect authorization code flow with PKCE
OIDC plays the same fundamental role as SAML — allowing identity to be shared across systems — but uses JSON tokens rather than XML and is designed for the modern web, mobile apps, and APIs. The Authorization Code Flow with PKCE is the standard flow for all modern applications.
- The client generates a
code_verifierandcode_challenge(PKCE). - The client redirects the user to the authorization endpoint:
GET /authorize?response_type=code&client_id=...&redirect_uri=...&scope=openid profile email&state=...&nonce=...&code_challenge=...&code_challenge_method=S256 - The IdP authenticates the user and evaluates conditional access policies.
- The IdP redirects to the client’s callback URL with an authorization code and the
statevalue. - The client verifies the returned
statematches what it sent, then POSTs to the token endpoint withgrant_type=authorization_code, thecode, theredirect_uri, and thecode_verifier. - The IdP validates the
code_verifieragainst the storedcode_challenge, verifies theredirect_urimatches the registered value, and authenticates the client. - The IdP returns an
access_token,id_token,refresh_token, and expiration metadata. - The client validates the
id_tokenJWT: verify the signature using the IdP’s JWKS, verifyiss,aud,exp,iat, andnonce(to prevent replay).
Claims, scopes, and how federation drives authorization
A common point of confusion is the relationship between authentication and authorization in an IdP. The identity provider handles authentication — proving who you are — but authorization — deciding what you are allowed to do — typically happens at the resource level rather than the IdP level. The IdP’s role in authorization is to issue a credential that carries the signals the resource server needs to make its own access decision.
In the OAuth 2.0 model, scopes are the mechanism through which clients declare what permissions they are requesting. A client that needs to read a user’s email requests scope=email. A client that needs to write calendar events requests scope=calendar.write. The IdP evaluates whether to grant those scopes based on the user’s entitlements and whether they have consented, then encodes the granted scopes in the issued access token.
At the resource server, authorization is enforced by inspecting the claims in the access token. Claims are statements about the principal that the IdP has certified: the user’s identifier (sub), their group memberships, their roles, their department, or any custom attributes derived from the directory. A resource server that exposes a payroll API might check that the access token contains a role: payroll-admin claim before processing a request. The IdP does not make that access decision; it certifies the facts, and the resource server decides what those facts imply for access.
This division matters for security design because it means an IdP can only influence authorization to the extent that it controls the claims it issues. If a user’s group memberships change, the directory must reflect that change before new tokens carry the updated claim. This is precisely why CAEP’s token-claims-change event exists: it allows the IdP to signal to resource servers that previously issued claims are no longer accurate, without waiting for the old access token to expire naturally.
Single Logout (SLO)
Single logout is the mechanism by which a user’s sign-out propagates to all applications that share the IdP session. Achieving reliable SLO is harder than SSO because it requires coordinating termination across multiple independent applications simultaneously.
SAML front-channel SLO uses browser redirects to sequentially notify each application of logout. The IdP redirects the browser to each SP’s SLO endpoint, which terminates the local session and redirects back. This is unreliable in practice: if any application in the chain is slow or unavailable, the redirect chain breaks and some sessions remain active.
OIDC back-channel logout (OpenID Connect Back-Channel Logout 1.0) is the most reliable modern approach. When a logout event occurs, the IdP sends a signed logout token JWT directly via HTTP POST to each registered application’s backchannel_logout_uri — server-to-server, bypassing the browser entirely. The logout token contains the iss, sub, session ID (sid), and a specific events claim identifying it as a logout event. The application validates the token and immediately terminates the corresponding server-side session. Back-channel logout is supported by Okta, Entra ID, and Auth0, and is the recommended approach for new application integrations.
OIDC front-channel logout uses hidden <iframe> tags on the IdP’s logout page to simultaneously trigger logout endpoints at each registered application. Browser restrictions on third-party cookies and iframe loading have made this approach increasingly unreliable and it is not recommended for new deployments.
What federation does inside the identity system
Regardless of protocol, federation plays the same architectural role. It takes a successful authentication event — along with the session and tokens produced by the IdP — and projects that identity outward in a form that other systems can rely on without re-authenticating the user. Federation depends on the directory for user attributes that populate claims, depends on the authentication engine for assurance level, and feeds into provisioning and access policies that determine what the user can actually do downstream.
Provisioning Engine
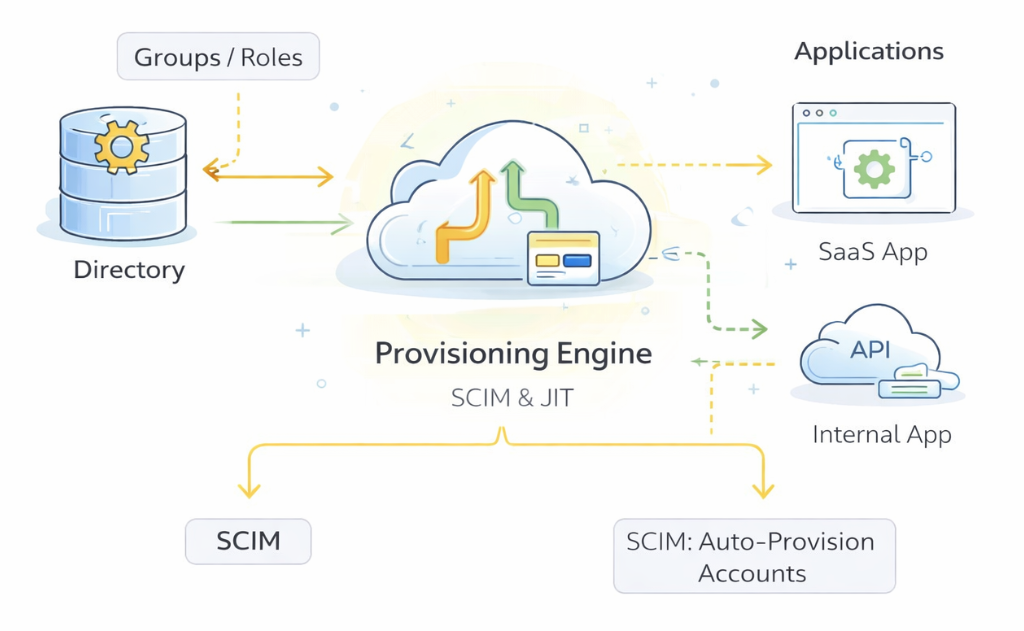
Provisioning addresses a problem distinct from authentication and federation: how user accounts are created and maintained inside other applications over time. Even when identity can be proven and shared through SSO, organizations still need a reliable way to ensure that people have the right accounts in the right systems — and that those accounts change as roles, teams, or employment status change.
Without automated provisioning, identity management quickly becomes fragile. New employees require administrators to log into every system and create accounts manually. When someone changes roles, those accounts need to be updated in multiple places. When someone leaves, every account must be tracked down and disabled. The result is slow onboarding, inconsistent access, and a significant security risk from forgotten or orphaned accounts that linger long after a person has moved on.
Provisioning automates this lifecycle by taking information from the directory — who a user is, what groups they belong to, their role and status — and using it to create, update, or disable accounts in downstream applications. Two primary mechanisms accomplish this.
Just-in-Time (JIT) provisioning
JIT provisioning is tightly coupled to the federation flow. Instead of creating an account ahead of time, an application waits until the user first authenticates via the identity provider.
- A user attempts to access an application for the first time.
- The application redirects them to the IdP, which authenticates the user.
- The IdP returns a federated identity assertion (SAML or OIDC) containing the user’s attributes.
- The application inspects the assertion — email, name, group membership — and automatically creates a local account if one does not already exist.
- The user gains access without a separate account creation step.
JIT provisioning minimizes administrative overhead and ensures accounts are only created when actually needed. Its limitation is that it handles account creation well but is less reliable for ongoing lifecycle management. Updates and terminations must be handled out-of-band unless the application explicitly processes attribute changes on every subsequent login.
SCIM provisioning
SCIM (System for Cross-domain Identity Management, RFC 7642–7644) is the standard protocol for automated, continuous user lifecycle management. SCIM defines a RESTful API that identity providers use to push identity changes to connected applications proactively, rather than waiting for a login event.
A SCIM-compatible application exposes standard endpoints:
GET /UsersandGET /Groups— list and filter existing users and groups.POST /Users— create a new user account.PATCH /Users/{id}— update specific attributes (e.g., role change, department change).DELETE /Users/{id}or a deactivation PATCH — disable or remove the account on termination.
The identity provider acts as the SCIM client, sending these operations to each connected application when identity events occur. The application becomes a downstream consumer of the IdP’s directory state rather than maintaining its own authoritative user store. SCIM enables hundreds of applications to stay in sync with a single directory without manual intervention.
HR-driven provisioning and the joiner-mover-leaver lifecycle
In large enterprises, the identity provider itself is rarely the authoritative source of workforce identity — the HR system is. Platforms like Workday, SAP SuccessFactors, and BambooHR contain the authoritative record of who is employed, in what role, in what department, and on what dates. HR-driven provisioning connects this source of truth to the identity stack so that identity lifecycle events flow automatically from the HR system into the IdP and then out to every connected application.
The lifecycle maps to three event types:
- Joiner — a new employee is added to the HR system. The IdP creates a directory record, assigns the user to appropriate groups based on role and department, and SCIM provisions accounts in all relevant applications. On day one, the new employee has everything they need without a manual ticket.
- Mover — an employee changes roles, departments, or locations. The HR system updates the record, the IdP modifies the directory entry and group memberships, and SCIM propagates the changes to all connected applications. Access to the old department’s tools is revoked; access to the new role’s tools is granted.
- Leaver — an employee is terminated. The HR system marks the record as inactive. The IdP disables the account, revokes active sessions, and SCIM disables or removes accounts in all connected applications. This should be automated and near-instantaneous; manual offboarding processes create windows of unauthorized access.
Deprovisioning and orphaned accounts
Deprovisioning — the leaver process — is consistently the weakest part of enterprise identity management. An account that remains active after its owner has left the organization is called an orphaned account. Orphaned accounts represent unauthorized access paths: former employees who retain working credentials, contractors whose engagements have ended, or service accounts tied to applications that have been decommissioned.
The OWASP Non-Human Identity Top 10 lists improper offboarding as the number one NHI risk, specifically because machine identity deprovisioning is even more neglected than human identity deprovisioning. A service account created for an application migration three years ago may still have active credentials and broad permissions long after anyone remembers it exists.
Automated provisioning through SCIM does not completely solve the orphaned account problem. SCIM covers applications that are registered with the IdP and have a SCIM connector. Applications that fall outside this scope — legacy systems, manually managed tools, shadow IT — require separate discovery and audit processes to identify and remediate orphaned accounts. Access reviews and periodic entitlement certifications, provided by IGA (Identity Governance and Administration) platforms, are the detective control for the gaps that SCIM cannot reach.
How provisioning fits into the whole system
Authentication proves identity. Federation shares identity. Provisioning installs identity where it needs to exist. It is deeply dependent on the directory, because user attributes and group memberships drive every provisioning decision. It is tightly coupled to federation, since many applications rely on SSO while being provisioned in the background. And it connects to conditional access and governance, since access may need to be revoked when risk changes or when entitlement reviews determine access is no longer appropriate.
Conditional Access Engine
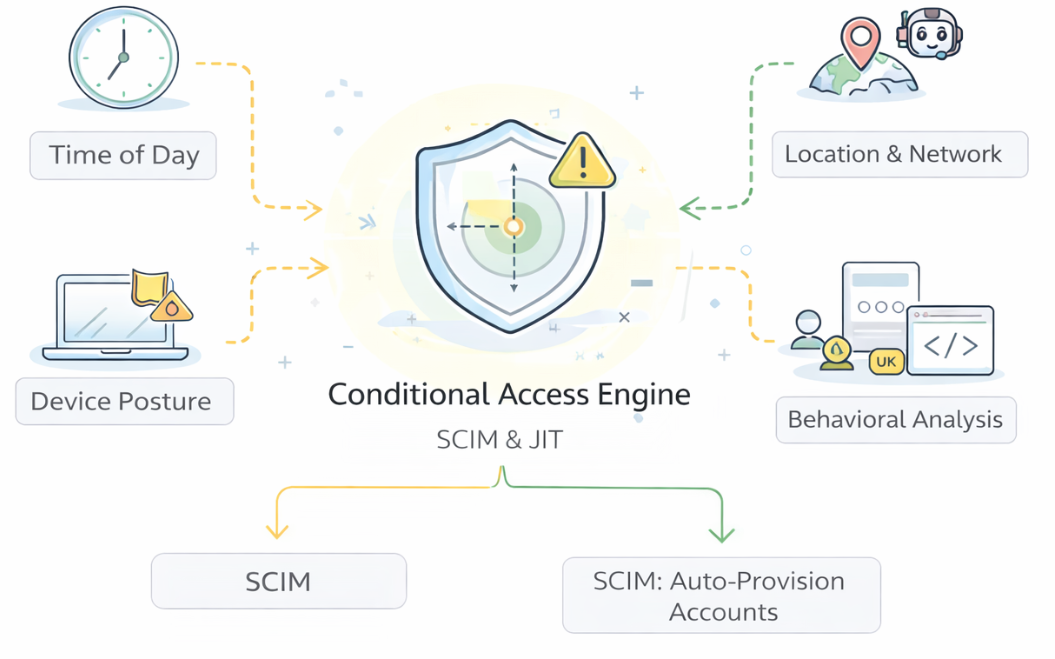
Conditional access determines whether an authentication event should be accepted, challenged, or rejected based on context. It is a policy and risk evaluation layer that operates at — and sometimes after — the login experience, continuously evaluating what is known about the request to decide whether to allow access, deny it, or require stronger verification.
Most modern identity providers no longer treat authentication as a binary event. Instead, they treat every login as a context-rich signal that can be evaluated in real time. Conditional access (also called adaptive MFA or risk-based authentication) makes this possible. It supplements standard authentication by incorporating intelligence about the user, the device, and the environment before allowing access to complete.
Conditional access policies typically draw on signals including:
- Time of day and login velocity: Logins outside normal hours or from a location that is geographically impossible given recent activity (“impossible travel”) flag as elevated risk.
- Network and location: Requests from unfamiliar countries, Tor exit nodes, known malicious IP ranges, or anonymizing proxies trigger additional scrutiny or denial.
- Device posture: Managed, MDM-enrolled corporate devices are trusted more than personal or unmanaged ones. Missing security patches, disabled disk encryption, or malware detections raise risk.
- Application sensitivity: Accessing email may require less scrutiny than accessing payroll, production infrastructure, or a secrets management system.
- User risk score: Signals from the identity threat detection layer, including leaked credential detection and anomalous behavior patterns.
These signals shape how authentication behaves. In low-risk scenarios, conditional access allows login to proceed normally. In elevated-risk scenarios, it requires step-up authentication. In high-risk scenarios, it may block access entirely or suspend the account pending investigation.
Where conditional access fits into identity flows
Conditional access is not confined to the initial login. It can appear across multiple points in the identity lifecycle:
- During onboarding and enrollment: Ensuring initial account creation occurs from a reasonable location and device, reducing fraudulent sign-up risk.
- During normal authentication: Dynamically adjusting requirements based on context — seamless access when signals look normal, tighter controls when something looks unusual.
- During account recovery: Applying the most stringent requirements, because recovery from a new device or unfamiliar location represents a high-risk event regardless of intent.
- Continuously post-authentication: Through CAEP, extending policy enforcement beyond the initial login into the ongoing session.
A concrete end-to-end scenario
- A user attempts to access an application. The application redirects them to the IdP.
- Before presenting a login prompt, the IdP gathers contextual signals: device type, IP address, geolocation, time of day, and recent login history.
- The conditional access engine evaluates the signals. Suppose the user is on an unmanaged device, accessing from an unfamiliar country, outside normal business hours. Risk is flagged as elevated.
- Instead of allowing a password login, the IdP requires step-up authentication — a hardware security key or a fresh passkey assertion from a trusted device.
- If the user satisfies the challenge, the IdP records the authentication method, assurance level, and context. The session is created with a stronger authentication record.
- The IdP issues a SAML assertion or OIDC token reflecting the user’s identity and authentication context. The application trusts it and grants access.
- If risk were determined to be too high — for example, the IP appears in a known-malicious threat feed — the IdP denies access entirely without prompting for credentials.
Continuous Access Evaluation (CAEP)
Traditional conditional access makes its decision at login time and then trusts the session until the token expires or the session times out. This creates a gap: if something changes after authentication — the user’s device is compromised, their account is suspended, their role changes, or an administrator revokes access — the existing access tokens remain valid until they expire. A one-hour access token remains a valid credential for up to an hour after revocation is intended.
Continuous Access Evaluation (CAEP) closes this gap. CAEP is part of the Shared Signals Framework (SSF), a set of OpenID Foundation specifications (finalized September 2, 2025) for a push-based webhook system that carries security events between identity systems and relying applications in near real-time.
The architecture involves a transmitter (typically the IdP or an endpoint security platform that detects a security-relevant event) and a receiver (an application that consumes the event and takes action). Events are delivered as signed Security Event Tokens (SETs) — JWTs sent via HTTP POST to a registered receiver endpoint.
CAEP defines specific event types:
- session-revoked — the session must end immediately. Triggers include admin-forced sign-out, suspicious activity detection, or a policy change that retroactively invalidates the session.
- credential-change — the user changed a credential (password reset, MFA factor enrollment or removal). Relying applications should require re-authentication.
- assurance-level-change — the authentication assurance level changed mid-session, for example because a strong MFA factor was removed.
- token-claims-change — user attributes that affect what the token says have changed (role, group membership, entitlement). Applications should re-evaluate access based on updated claims.
- device-compliance-change — MDM reports the device is no longer compliant (jailbroken, out-of-date OS, required security software removed). Access should be restricted or terminated.
When an application receives a CAEP event, it can immediately revoke the affected session without waiting for token expiry. Microsoft Entra ID and its resource services (Exchange Online, SharePoint Online) support CAE natively, with near-real-time session termination propagation. Okta supports SSF/CAEP as both transmitter and receiver, with integrations from CrowdStrike (endpoint compromise signals) and Jamf (device compliance changes).
IPSIE and the forward direction
The Interoperability Profile for Secure Identity in the Enterprise (IPSIE) working group, launched at the OpenID Foundation in October 2024 with founding members including Okta, Microsoft, and Ping Identity, aims to define opinionated, secure-by-default enterprise profiles across OpenID Connect, OAuth 2.0, SCIM, and the Shared Signals Framework. Its goal is to reduce the fragmentation caused by too many optional features across these standards and create a baseline of interoperability across IdPs and applications. IPSIE is in active development and represents the forward direction for enterprise identity federation standards.
Non-Human Identity
For most of the history of enterprise identity management, an “identity” meant a person. Identity providers were designed around human lifecycle events: hiring, role changes, and termination. This assumption no longer describes the reality of enterprise environments.
In modern organizations, non-human identities (NHIs) — service accounts, OAuth client applications, API keys, machine credentials, workload identities, and AI agent identities — outnumber human identities by 50 to 100 to one. This ratio is growing rapidly as AI agent deployment scales. OWASP published a dedicated Non-Human Identity Top 10 in June 2025 in recognition of how significant this attack surface has become: 80% of identity-related breaches in recent years involved a compromised NHI of some kind.
Types of non-human identity
Non-human identities span several categories, each with different characteristics:
- Service accounts — directory accounts used by applications or automated processes rather than humans. Often created with broad permissions to simplify initial integration and then left with those permissions indefinitely.
- OAuth clients — applications registered with the IdP that obtain tokens to call APIs on behalf of users or on their own behalf (client credentials flow). Each registered application has a client ID and authenticates with a client secret, certificate, or key.
- API keys — static secrets used to authenticate to APIs directly, typically without the full OAuth flow. Commonly stored in code, configuration files, or environment variables, making them frequent targets for accidental exposure.
- Cloud-managed identities — platform-assigned identities for compute resources (AWS IAM roles for EC2 instances, Azure Managed Identities, GCP Service Accounts). These are tied to the infrastructure rather than a credential that needs to be stored or rotated manually.
- Workload identities — cryptographic identities assigned to individual services in a distributed system, enabling mTLS-based service-to-service authentication without static credentials.
- AI agent identities — ephemeral identities assigned to AI agents for the duration of a task, discussed below.
How NHI differs from human identity
NHI management requires a fundamentally different approach from human identity management because the properties of machine identities are different in almost every dimension that matters:
- Lifecycle: Human identities persist for years; machine identities may be created and destroyed in minutes, or may last indefinitely without any defined lifecycle at all.
- Authentication: Humans use passwords and second factors; machines use client secrets, certificates, or platform-provided credentials.
- Scale: Human directories have thousands to millions of users; NHI inventories have tens to hundreds of millions of entries in large environments.
- Offboarding: Human offboarding is triggered by HR events; NHI offboarding must be automated or it does not happen. There is no equivalent of an HR termination event for a service account tied to a deprecated microservice.
- Discovery: HR systems provide a canonical inventory of humans; there is no equivalent for NHIs. Continuous discovery is required because NHIs are created through automated processes, infrastructure-as-code, CI/CD pipelines, and developer convenience without central registration.
Workload identity and SPIFFE/SPIRE
In microservices and containerized environments, managing credentials for service-to-service communication is one of the hardest NHI problems. SPIFFE (Secure Production Identity Framework for Everyone), a CNCF graduated project, addresses this with a vendor-neutral workload identity framework.
SPIFFE defines a SPIFFE ID — a URI-formatted identity such as spiffe://example.com/payments/invoicing-service — that uniquely identifies a workload within a trust domain. This identity is encoded in a SVID (SPIFFE Verifiable Identity Document), either an X.509 certificate with the SPIFFE ID in the URI SAN extension or a JWT. SVIDs are automatically rotated (typically every hour) by a SPIRE Agent running on each node, which performs workload attestation using OS-level signals to confirm the identity of each process before issuing credentials.
The result is that services can authenticate to each other using mTLS with automatically rotating certificates, without any static credentials stored in configuration files. A compromised container has credentials valid for only until the next rotation cycle — typically under an hour.
AI agent identity
AI agents present unique identity challenges that existing NHI frameworks were not designed for. Agents are often ephemeral, created and destroyed per task. They may chain to other agents through delegation. They require scoped access to specific tools, APIs, and data stores. And they must produce auditable records of what they accessed and why.
Emerging patterns for AI agent identity (as of 2025–2026) include:
- OAuth 2.0 client credentials with short-lived, narrowly scoped tokens per agent instance. The agent authenticates using a registered client identity, receives a token valid for the duration of the task, and the token expires automatically.
- Delegation tokens: A human user delegates a bounded subset of their permissions to an agent for a specific time window. The agent cannot exceed the permissions of the delegating user and the delegation expires automatically.
- MCP OAuth 2.1: The Model Context Protocol (finalized 2025) uses OAuth 2.1 — which mandates PKCE and removes the implicit flow — for authorizing AI tool connections. Each tool access is treated as an OAuth-protected API call with explicit user consent and scoped authorization.
OWASP NHI Top 10 (2025)
The OWASP Non-Human Identity Top 10, published June 2025, identifies the ten most critical NHI risks:
- Improper offboarding — NHIs not deactivated when the associated service or application is decommissioned.
- Secret leakage — API keys, tokens, and certificates accidentally exposed in source code, container images, or CI/CD logs.
- Vulnerable third-party NHI — excessive permissions granted to third-party integrations; supply chain risk from compromised vendor identities.
- Insecure authentication — NHIs using weak authentication methods such as static secrets with no rotation.
- Overprivileged NHI — excessive permissions that violate least privilege, often granted at initial setup and never reduced.
- Insecure cloud deployment configurations — misconfigured IAM roles and service account bindings in cloud environments.
- Long-lived secrets — API keys and client secrets that never expire, maximizing the blast radius of a compromise.
- Environment isolation failures — NHIs shared across development, staging, and production, so a compromised staging credential reaches production.
- NHI reuse — the same credential or service account used by multiple services, making blast radius analysis impossible.
- Human use of NHI — engineers using service account credentials for interactive access, bypassing individual audit trails and policy controls.
Key Management and Signing Infrastructure
The cryptographic trust model that makes federation work — SAML assertions signed by the IdP, OIDC tokens signed by the IdP, applications trusting tokens because they can verify the signature — depends entirely on the integrity of the IdP’s signing keys. Key management is not a peripheral concern; it is the root of trust for the entire identity system.
The JWKS endpoint
Every OIDC provider exposes a JWKS (JSON Web Key Set) endpoint at the standard path /.well-known/jwks.json. This publicly accessible document contains the IdP’s current public signing keys. Relying parties fetch this document to obtain the public keys they need to verify token signatures.
Each key in the JWKS includes:
- kty — key type:
RSAorEC(elliptic curve). - use — intended use:
sigfor signing orencfor encryption. - kid — key ID: a unique identifier for this specific key. JWT headers include a
kidfield that tells the receiver which key to use for verification. - alg — the signing algorithm:
RS256,ES256,PS256, and so on. - The public key material itself (
nandefor RSA;x,y, andcrvfor EC).
Relying parties cache the JWKS (respecting Cache-Control headers) and use the kid in each JWT header to select the correct key. If a JWT arrives with an unrecognized kid, the relying party should refresh the JWKS to check for a recently rotated key — but should rate-limit these refreshes to prevent abuse.
Signing algorithms
Three RSA and elliptic curve algorithms dominate current IdP deployments:
- RS256 (RSA PKCS#1 v1.5 + SHA-256) — the most widely deployed algorithm due to broad legacy support. Still secure, but has known theoretical weaknesses compared to PSS padding.
- PS256 (RSA-PSS + SHA-256) — considered best practice for RSA-based signing due to improved security properties over PKCS#1 v1.5. Recommended for new deployments where RS256 backward compatibility is not required.
- ES256 (ECDSA + P-256 curve + SHA-256) — offers equivalent security to 3072-bit RSA with significantly smaller keys and faster operations. Preferred for new deployments where broad compatibility is not a constraint.
Hardware security modules
Production identity providers store private signing keys in hardware security modules (HSMs) or cloud KMS services rather than in software key stores. An HSM generates keys internally and never exports the private key material. All signing operations are performed inside the HSM via API; the IdP application requests a signature without ever seeing the raw private key bytes.
Cloud providers offer managed HSM-backed key services: AWS CloudHSM, Azure Key Vault with HSM backing, and GCP Cloud HSM. On-premises IdPs such as Ping Identity and ForgeRock commonly use Thales Luna or Entrust nShield HSMs. FIPS 140-2 Level 3 validation is the standard requirement for government and regulated industry deployments.
HSM protection raises the bar for key theft significantly: an attacker who compromises the IdP server cannot extract the private key. However, as noted in the context of the Golden SAML attack, an attacker who has fully compromised the IdP host can still use the HSM to sign arbitrary assertions at runtime — by calling the signing API from the compromised server. HSMs prevent key extraction; they do not prevent misuse on a compromised host.
Key rotation
Signing key rotation is the process of replacing the active signing key with a new one, retiring the old key after outstanding tokens expire. Zero-downtime rotation requires advertising both the old and new keys simultaneously during a grace period so that relying parties can discover the new key before the old one stops being used for new signatures.
The recommended four-phase rotation process is:
- Publish new key — generate a new key pair in the HSM and add the new public key to the JWKS endpoint. The old key remains active for signing.
- Grace period (typically 1–7 days) — allow relying parties time to refresh their JWKS cache and discover the new key’s
kid. No new tokens are signed with the new key yet. - Promote new key — switch active signing to the new key. All new tokens are signed with the new key. Tokens previously signed with the old key remain valid at relying parties until they expire naturally.
- Retire old key — after the maximum lifetime of any token signed with the old key has elapsed, remove the old key from the JWKS endpoint.
Rotation frequency varies by organization. Some rotate every 90 days; others rotate monthly or more frequently for high-security environments. Google rotates consumer identity signing keys on a weekly cadence. The minimum requirement is to have a tested emergency rotation procedure that can be executed rapidly when a compromise is suspected, including the ability to immediately invalidate all tokens signed with a compromised key by mass-revoking refresh tokens and forcing re-authentication.
Identity Threat Detection and Response
An identity provider handles authentication and access policy, but it also has comprehensive visibility into identity events across the enterprise: every login attempt, every failed authentication, every policy decision, every token issuance. Identity Threat Detection and Response (ITDR) is the discipline of analyzing this telemetry to detect identity-based attacks and trigger automated responses.
ITDR emerged as a named security category in 2022 because traditional SIEM and SOAR tools lacked the identity-specific context to detect these attacks at the signal layer. A SIEM can correlate logs from many sources, but it requires analyst-written rules and is largely retrospective. ITDR is purpose-built for identity signals, incorporating identity-specific machine learning models that establish behavioral baselines per user, per device, and per application, and can act in real time during authentication — blocking a session before it is established rather than alerting on it after the fact.
Signal sources
Modern ITDR systems draw from multiple signal sources simultaneously:
- IdP authentication logs — login success and failure patterns, MFA bypass attempts, unusual application access sequences, geographic anomalies.
- Endpoint and EDR telemetry — device health signals from CrowdStrike Falcon, Microsoft Defender for Endpoint, or similar, delivered via CAEP when device compromise is detected.
- MDM compliance signals — Jamf, Intune, or similar platforms reporting device posture changes.
- Network signals — geolocation, Tor and VPN detection, known malicious IP reputation.
- Dark web and leaked credential feeds — monitoring for credentials associated with the organization appearing in breach databases or paste sites.
- Behavioral analytics (UEBA) — baseline deviation scoring that flags users whose behavior (access patterns, data volumes, application usage) differs significantly from their established norm.
Entra ID Protection
Microsoft Entra ID Protection provides automated user risk and sign-in risk scoring for Entra-authenticated environments. It evaluates risk at two levels:
Real-time sign-in risk detections (evaluated at authentication time) include: sign-in from an anonymized IP address (Tor, known VPN services); atypical travel (two sign-ins from geographically inconsistent locations within a timeframe that rules out legitimate travel); sign-in from a malware-linked IP; unfamiliar sign-in properties (new device, location, or network ASN for this user); password spray patterns; suspicious browser behavior; and token anomalies (access token or session cookie reused from a different IP or device than its issuance context).
Offline user risk detections (processed asynchronously and contributing to a persistent user risk score) include: leaked credentials discovered in dark web monitoring; anomalous sign-in activity patterns; and additional signals that take longer to process. User risk scores (low, medium, high) feed directly into Conditional Access policies — a user scored as high risk can be blocked from accessing applications or required to perform a password reset before proceeding.
Okta ThreatInsight
Okta ThreatInsight operates as a cross-tenant threat intelligence layer, aggregating authentication telemetry across Okta’s customer base to identify malicious IP addresses conducting password spraying, credential stuffing, and brute-force campaigns at scale. When an IP is identified as malicious across the network, Okta can block or challenge authentication from that IP across all tenants — providing early warning to organizations that have not yet seen attacks from that source. As of 2025, Okta reported blocking more than 15 billion malicious logins across its customer base through ThreatInsight.
Okta’s Identity Threat Protection (GA 2024) extends this to continuous post-authentication risk evaluation. It monitors sessions after login, ingesting signals from CAEP-connected sources such as CrowdStrike and Jamf, and can trigger forced re-authentication, Universal Logout (back-channel logout propagated to all connected applications), or SOAR playbooks when risk crosses a threshold.
How ITDR connects to the identity stack
ITDR is not a standalone product that operates independently of the identity provider. It is most effective when tightly integrated with the conditional access engine and CAEP infrastructure. Risk scores produced by the ITDR layer feed into conditional access policies, dynamically raising the authentication requirement or blocking access based on current threat intelligence. CAEP-based session revocation allows the ITDR system to terminate active sessions in near real-time when a threat is detected, rather than waiting for token expiry. The identity provider’s audit log provides the primary data source for ITDR analysis, which in turn produces signals that modify how the conditional access engine behaves for at-risk identities.
Putting the Architecture Together
A request traced from login to API call
Tracing a single request through the full architecture makes the component relationships concrete. Consider a user authenticating from an unfamiliar device and calling a protected API that requires elevated assurance:
- Directory lookup. The user navigates to an application and is redirected to the IdP with an OAuth 2.0 authorization request. The IdP looks up the user in the directory to resolve their attributes, group memberships, and registered authentication methods.
- Conditional access evaluation. Before presenting a login prompt, the conditional access engine evaluates context: device is unmanaged, location is unfamiliar. It determines that a phishing-resistant second factor is required.
- Authentication engine. The IdP presents a FIDO2 passkey challenge. The user’s device signs the challenge with the device-bound private key. The IdP verifies the signature against the registered public key in the directory. Authentication succeeds at AAL2. The session stores
amr: hwkand the achieved assurance level. - Token issuance. The IdP generates an authorization code via the PKCE flow. The client exchanges the code for an access token and ID token. The access token is a JWT signed with the IdP’s private signing key (referenced by
kidin the JWKS endpoint). It carriessub,aud,exp,amr,scope, and the user’s role claims derived from their directory group memberships. - Federation to the application. The client discovers the JWKS URI from
/.well-known/openid-configurationand validates the ID token signature,iss,aud, andnonce. The application creates a local session. The access token is stored for use with the resource API. - API call. The client presents the access token (as a Bearer or DPoP-bound token) to the resource server. The resource server validates the JWT signature using the JWKS, checks
aud,exp, andacr, and confirms the user’s role claim authorizes the operation. The request is granted. - Continuous access evaluation. During the session, the ITDR layer detects a device compliance change from MDM. CAEP delivers a device-compliance-change event to the resource server. The resource server terminates the active session immediately — without waiting for token expiry — and the user must re-authenticate.
Every component in the architecture contributed to this single transaction. The directory provided user attributes and registered authentication methods. The authentication engine enforced the assurance requirement. Token issuance carried identity claims across the trust boundary. The federation layer projected those claims to the application. The provisioning engine had already ensured the account existed in the resource system. CAEP closed the gap that static token expiration would have left open.
Each component of an identity provider solves a distinct problem, but they function as a coherent system because each depends on the others. The directory is the foundation that every other component reads from. The authentication engine builds confidence in who the user is and records that confidence as session state. Token lifecycle management translates that session state into portable, signed credentials that travel through the enterprise. The federation engine projects those credentials to downstream applications using standardized protocols. The provisioning engine ensures that accounts exist in the right places and are kept in sync as identity changes. The conditional access engine continuously evaluates whether ongoing access is appropriate given current context, and CAEP extends that evaluation to post-authentication sessions. Non-human identity, key management, and ITDR are not optional additions — they are structural requirements for any identity system operating at enterprise scale.
Understanding identity providers in this way — as a layered control plane rather than a login service — makes it possible to reason clearly about how these systems are designed, where their security assumptions live, and what happens when those assumptions fail. It also provides the vocabulary to evaluate the real-world tradeoffs that every identity architecture involves: between usability and assurance, between session longevity and revocation speed, between operational simplicity and blast radius containment. Those tradeoffs are present in every IdP deployment, and making them well requires understanding what each component is doing and why.